
Deep reinforcement studying (DRL) is transitioning from a analysis subject targeted on recreation taking part in to a know-how with real-world functions. Notable examples embrace DeepMind’s work on controlling a nuclear reactor or on bettering Youtube video compression, or Tesla making an attempt to make use of a way impressed by MuZero for autonomous automobile conduct planning. However the thrilling potential for actual world functions of RL also needs to include a wholesome dose of warning – for instance RL insurance policies are well-known to be weak to exploitation, and strategies for secure and strong coverage growth are an lively space of analysis.
Similtaneously the emergence of highly effective RL programs in the actual world, the general public and researchers are expressing an elevated urge for food for truthful, aligned, and secure machine studying programs. The main focus of those analysis efforts so far has been to account for shortcomings of datasets or supervised studying practices that may hurt people. Nevertheless the distinctive capacity of RL programs to leverage temporal suggestions in studying complicates the sorts of dangers and security issues that may come up.
This submit expands on our current whitepaper and analysis paper, the place we purpose for instance the totally different modalities harms can take when augmented with the temporal axis of RL. To fight these novel societal dangers, we additionally suggest a brand new form of documentation for dynamic Machine Studying programs which goals to evaluate and monitor these dangers each earlier than and after deployment.
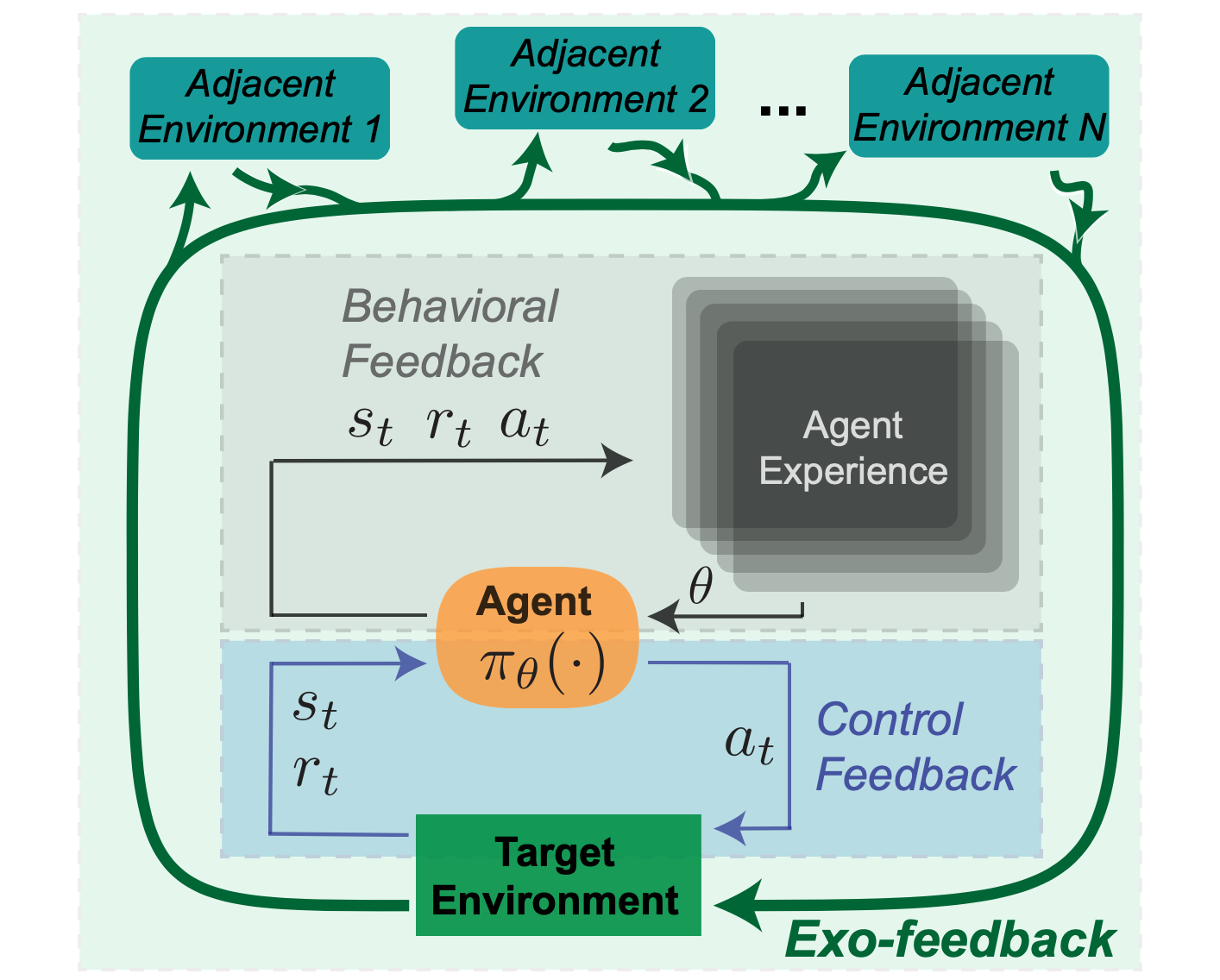
Reinforcement studying programs are sometimes spotlighted for his or her capacity to behave in an surroundings, fairly than passively make predictions. Different supervised machine studying programs, reminiscent of pc imaginative and prescient, devour information and return a prediction that can be utilized by some resolution making rule. In distinction, the attraction of RL is in its capacity to not solely (a) straight mannequin the impression of actions, but in addition to (b) enhance coverage efficiency routinely. These key properties of performing upon an surroundings, and studying inside that surroundings will be understood as by contemplating the various kinds of suggestions that come into play when an RL agent acts inside an surroundings. We classify these suggestions varieties in a taxonomy of (1) Management, (2) Behavioral, and (3) Exogenous suggestions. The primary two notions of suggestions, Management and Behavioral, are straight throughout the formal mathematical definition of an RL agent whereas Exogenous suggestions is induced because the agent interacts with the broader world.
1. Management Suggestions
First is management suggestions – within the management programs engineering sense – the place the motion taken will depend on the present measurements of the state of the system. RL brokers select actions based mostly on an noticed state in line with a coverage, which generates environmental suggestions. For instance, a thermostat activates a furnace in line with the present temperature measurement. Management suggestions offers an agent the flexibility to react to unexpected occasions (e.g. a sudden snap of chilly climate) autonomously.
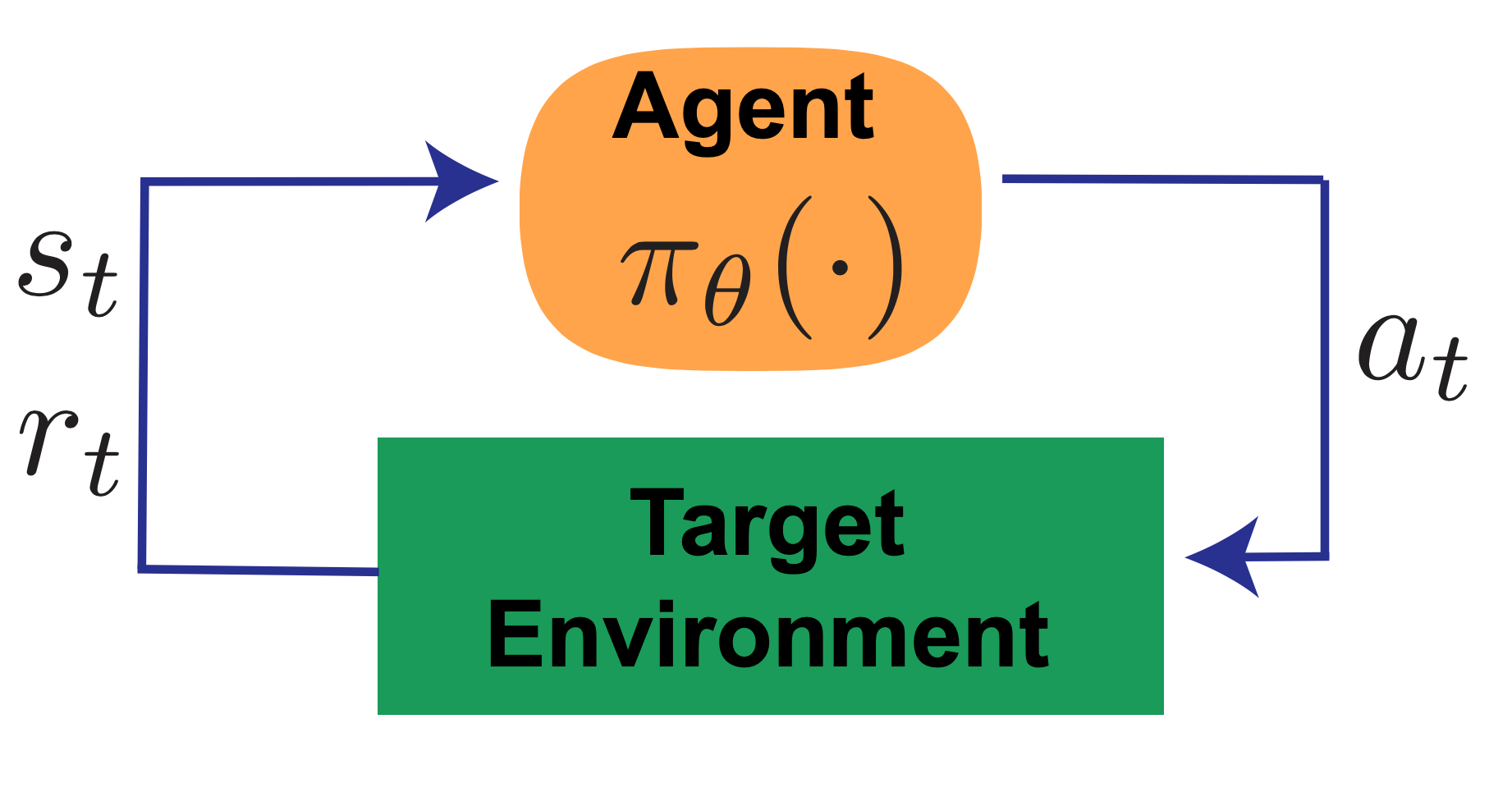
Determine 1: Management Suggestions.
2. Behavioral Suggestions
Subsequent in our taxonomy of RL suggestions is ‘behavioral suggestions’: the trial and error studying that allows an agent to enhance its coverage by interplay with the surroundings. This might be thought-about the defining function of RL, as in comparison with e.g. ‘classical’ management idea. Insurance policies in RL will be outlined by a set of parameters that decide the actions the agent takes sooner or later. As a result of these parameters are up to date by behavioral suggestions, these are literally a mirrored image of the info collected from executions of previous coverage variations. RL brokers will not be absolutely ‘memoryless’ on this respect–the present coverage will depend on saved expertise, and impacts newly collected information, which in flip impacts future variations of the agent. To proceed the thermostat instance – a ‘good dwelling’ thermostat may analyze historic temperature measurements and adapt its management parameters in accordance with seasonal shifts in temperature, as an example to have a extra aggressive management scheme throughout winter months.
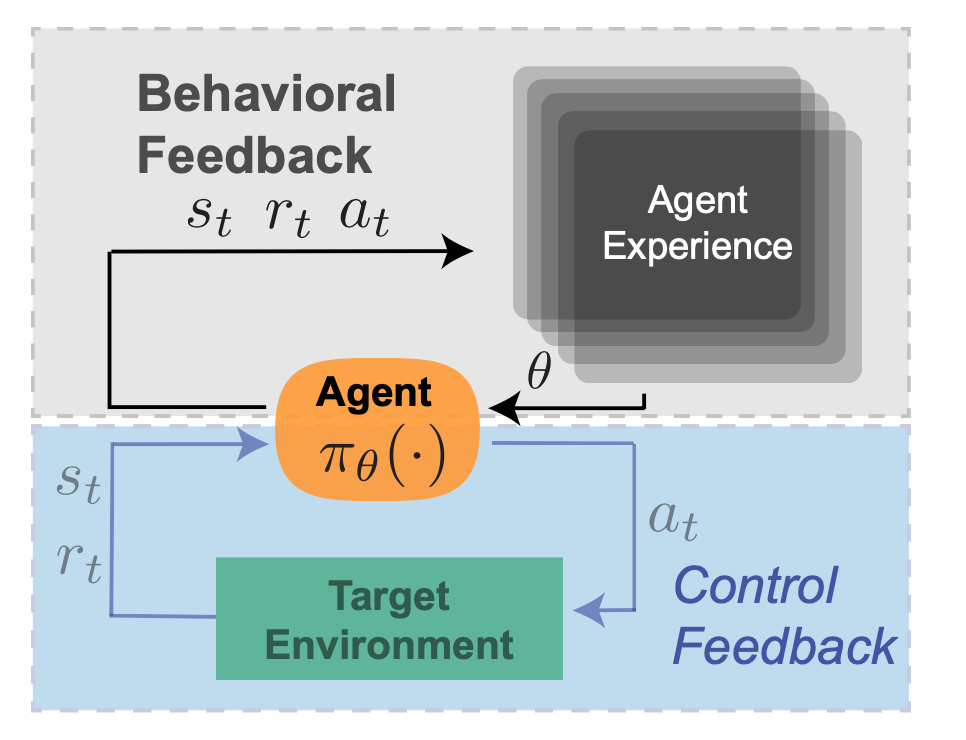
Determine 2: Behavioral Suggestions.
3. Exogenous Suggestions
Lastly, we are able to think about a 3rd type of suggestions exterior to the required RL surroundings, which we name Exogenous (or ‘exo’) suggestions. Whereas RL benchmarking duties could also be static environments, each motion in the actual world impacts the dynamics of each the goal deployment surroundings, in addition to adjoining environments. For instance, a information suggestion system that’s optimized for clickthrough might change the way in which editors write headlines in direction of attention-grabbing clickbait. On this RL formulation, the set of articles to be advisable could be thought-about a part of the surroundings and anticipated to stay static, however publicity incentives trigger a shift over time.
To proceed the thermostat instance, as a ‘good thermostat’ continues to adapt its conduct over time, the conduct of different adjoining programs in a family may change in response – as an example different home equipment may devour extra electrical energy as a consequence of elevated warmth ranges, which may impression electrical energy prices. Family occupants may additionally change their clothes and conduct patterns as a consequence of totally different temperature profiles throughout the day. In flip, these secondary results may additionally affect the temperature which the thermostat screens, resulting in an extended timescale suggestions loop.
Destructive prices of those exterior results won’t be specified within the agent-centric reward operate, leaving these exterior environments to be manipulated or exploited. Exo-feedback is by definition tough for a designer to foretell. As an alternative, we suggest that it needs to be addressed by documenting the evolution of the agent, the focused surroundings, and adjoining environments.
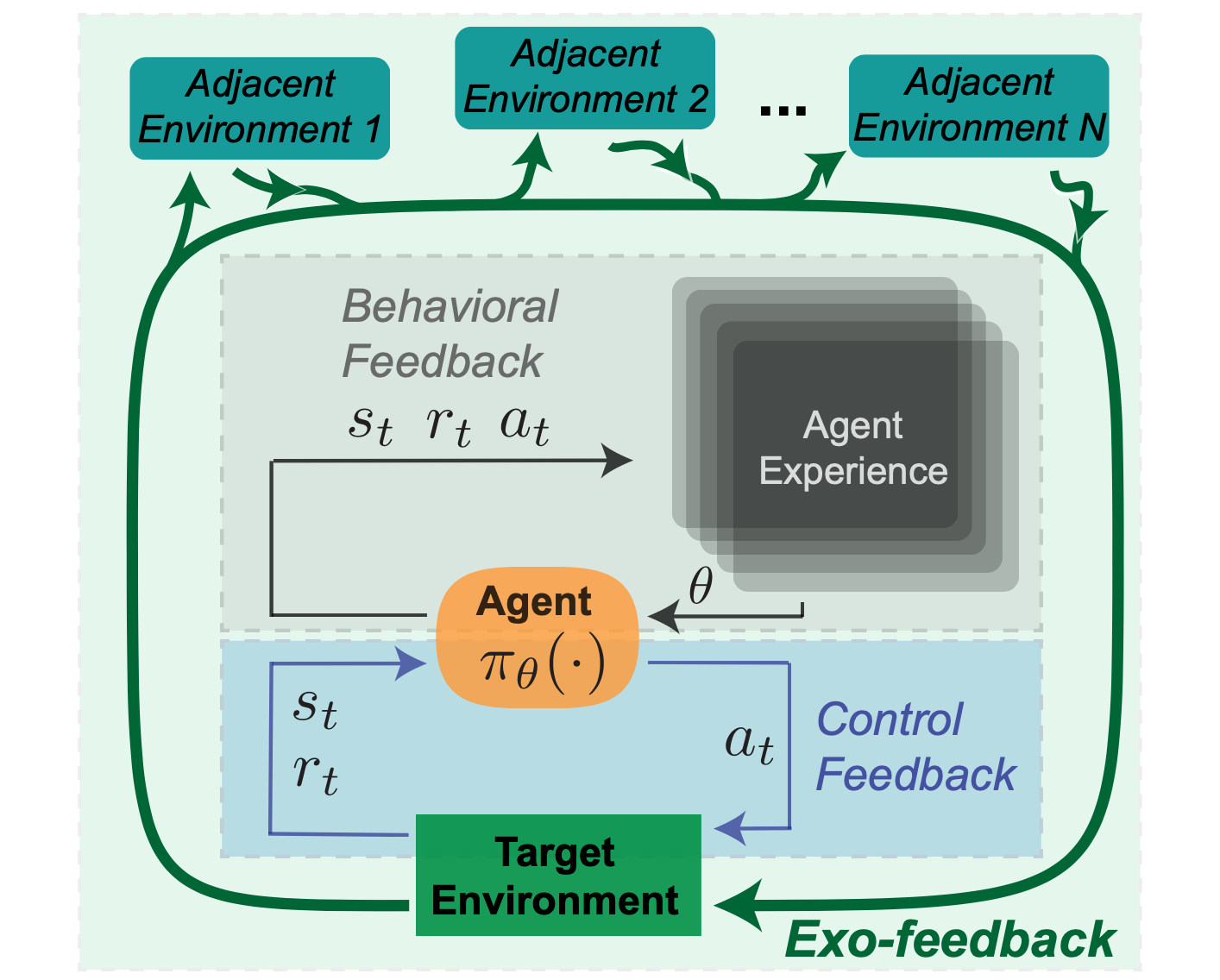
Determine 3: Exogenous (exo) Suggestions.
Let’s think about how two key properties can result in failure modes particular to RL programs: direct motion choice (by way of management suggestions) and autonomous information assortment (by way of behavioral suggestions).
First is decision-time security. One present observe in RL analysis to create secure selections is to enhance the agent’s reward operate with a penalty time period for sure dangerous or undesirable states and actions. For instance, in a robotics area we would penalize sure actions (reminiscent of extraordinarily massive torques) or state-action tuples (reminiscent of carrying a glass of water over delicate tools). Nevertheless it’s tough to anticipate the place on a pathway an agent might encounter a vital motion, such that failure would end in an unsafe occasion. This facet of how reward capabilities work together with optimizers is very problematic for deep studying programs, the place numerical ensures are difficult.
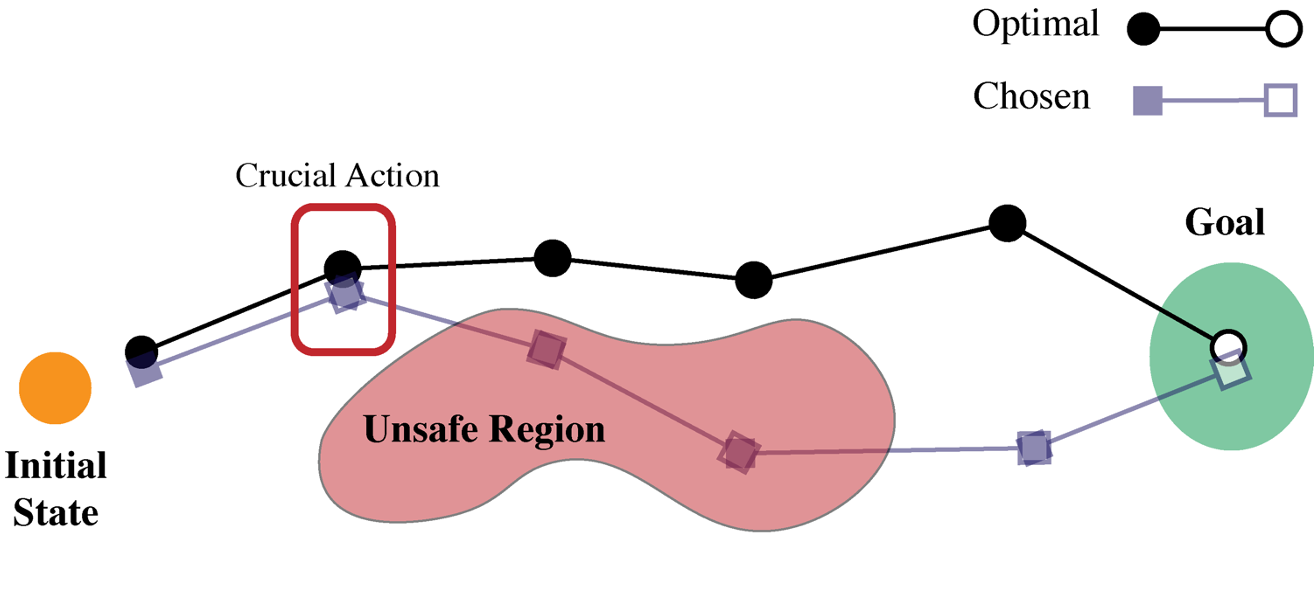
Determine 4: Choice time failure illustration.
As an RL agent collects new information and the coverage adapts, there’s a complicated interaction between present parameters, saved information, and the surroundings that governs evolution of the system. Altering any one among these three sources of data will change the long run conduct of the agent, and furthermore these three elements are deeply intertwined. This uncertainty makes it tough to again out the reason for failures or successes.
In domains the place many behaviors can probably be expressed, the RL specification leaves quite a lot of components constraining conduct unsaid. For a robotic studying locomotion over an uneven surroundings, it will be helpful to know what alerts within the system point out it’ll be taught to seek out a better route fairly than a extra complicated gait. In complicated conditions with much less well-defined reward capabilities, these supposed or unintended behaviors will embody a wider vary of capabilities, which can or might not have been accounted for by the designer.
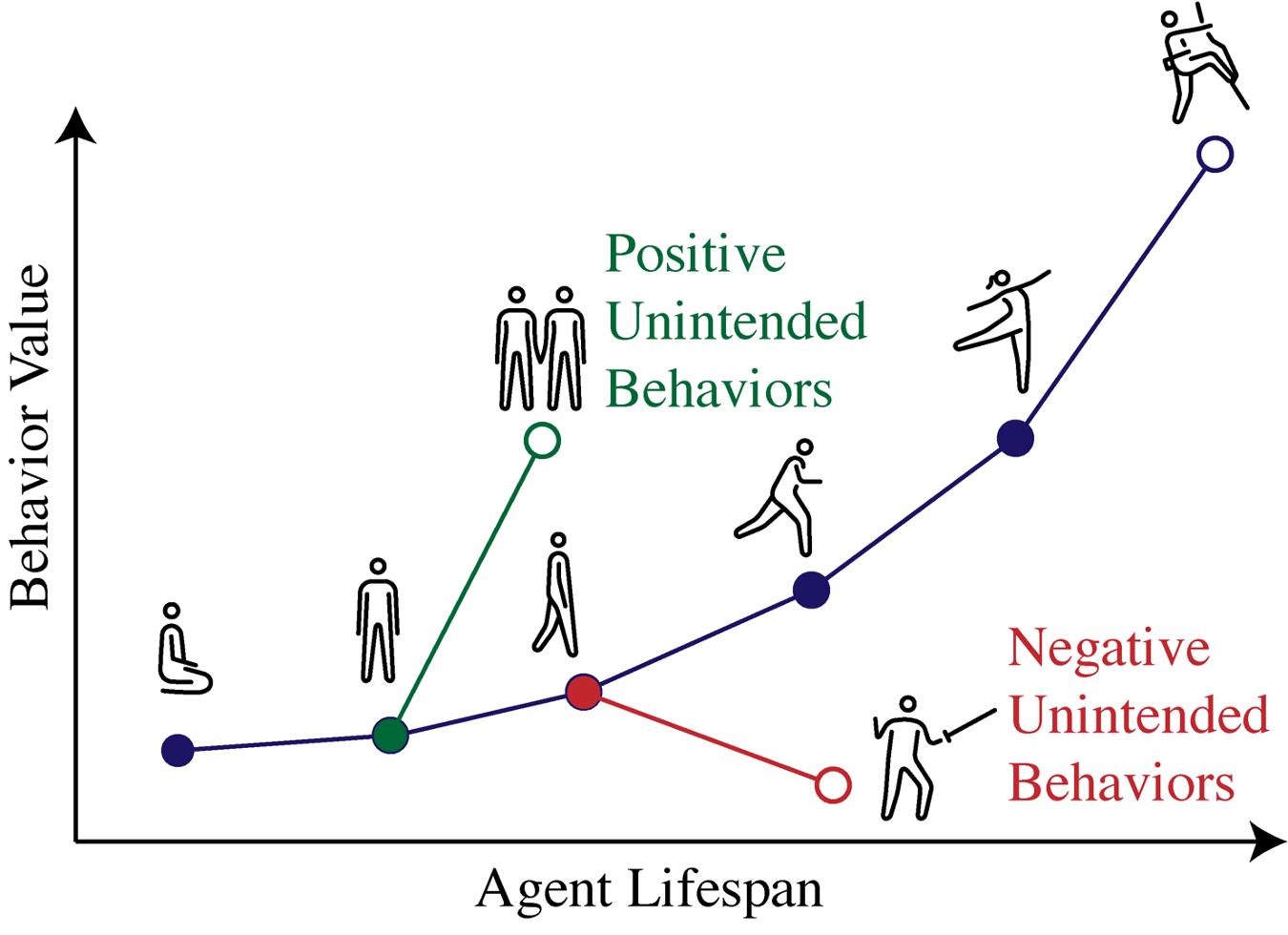
Determine 5: Conduct estimation failure illustration.
Whereas these failure modes are intently associated to manage and behavioral suggestions, Exo-feedback doesn’t map as clearly to 1 sort of error and introduces dangers that don’t match into easy classes. Understanding exo-feedback requires that stakeholders within the broader communities (machine studying, software domains, sociology, and many others.) work collectively on actual world RL deployments.
Right here, we focus on 4 sorts of design decisions an RL designer should make, and the way these decisions can have an effect upon the socio-technical failures that an agent may exhibit as soon as deployed.
Scoping the Horizon
Figuring out the timescale on which aRL agent can plan impacts the attainable and precise conduct of that agent. Within the lab, it might be widespread to tune the horizon size till the specified conduct is achieved. However in actual world programs, optimizations will externalize prices relying on the outlined horizon. For instance, an RL agent controlling an autonomous automobile can have very totally different objectives and behaviors if the duty is to remain in a lane, navigate a contested intersection, or route throughout a metropolis to a vacation spot. That is true even when the target (e.g. “decrease journey time”) stays the identical.
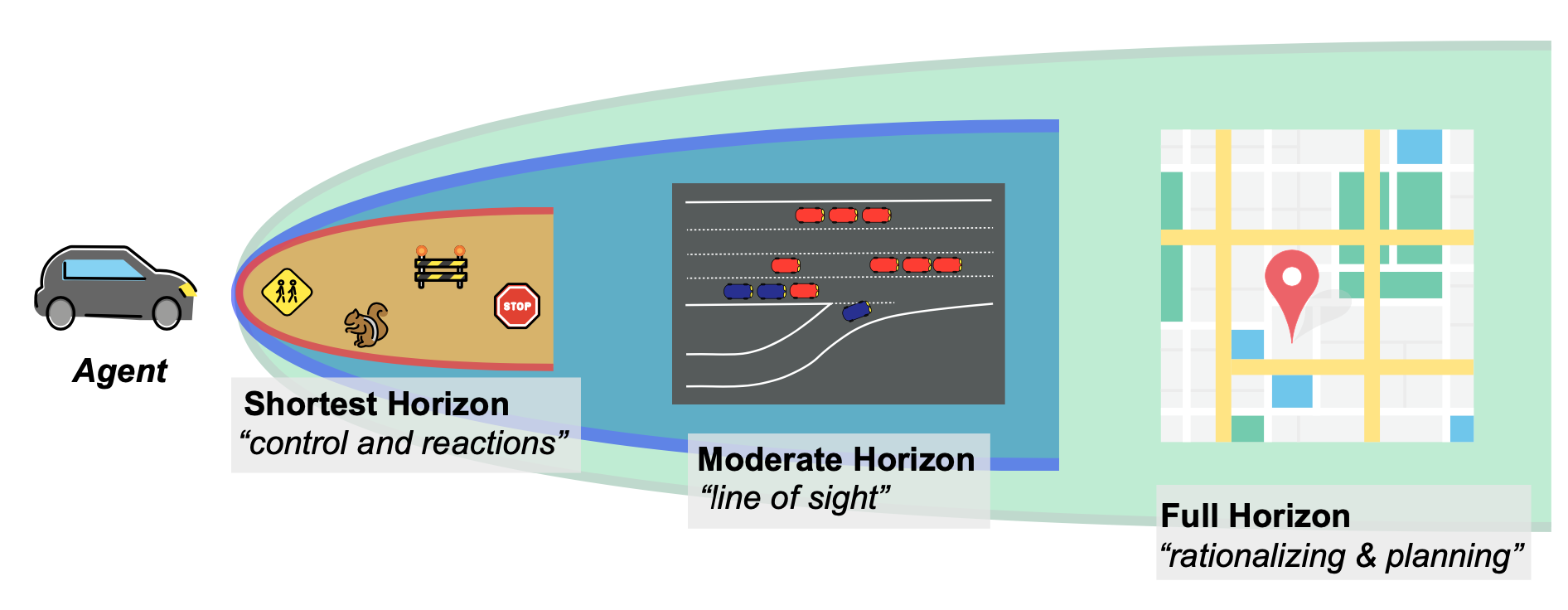
Determine 6: Scoping the horizon instance with an autonomous automobile.
Defining Rewards
A second design selection is that of truly specifying the reward operate to be maximized. This instantly raises the well-known threat of RL programs, reward hacking, the place the designer and agent negotiate behaviors based mostly on specified reward capabilities. In a deployed RL system, this typically ends in surprising exploitative conduct – from weird online game brokers to inflicting errors in robotics simulators. For instance, if an agent is introduced with the issue of navigating a maze to succeed in the far facet, a mis-specified reward may consequence within the agent avoiding the duty solely to attenuate the time taken.
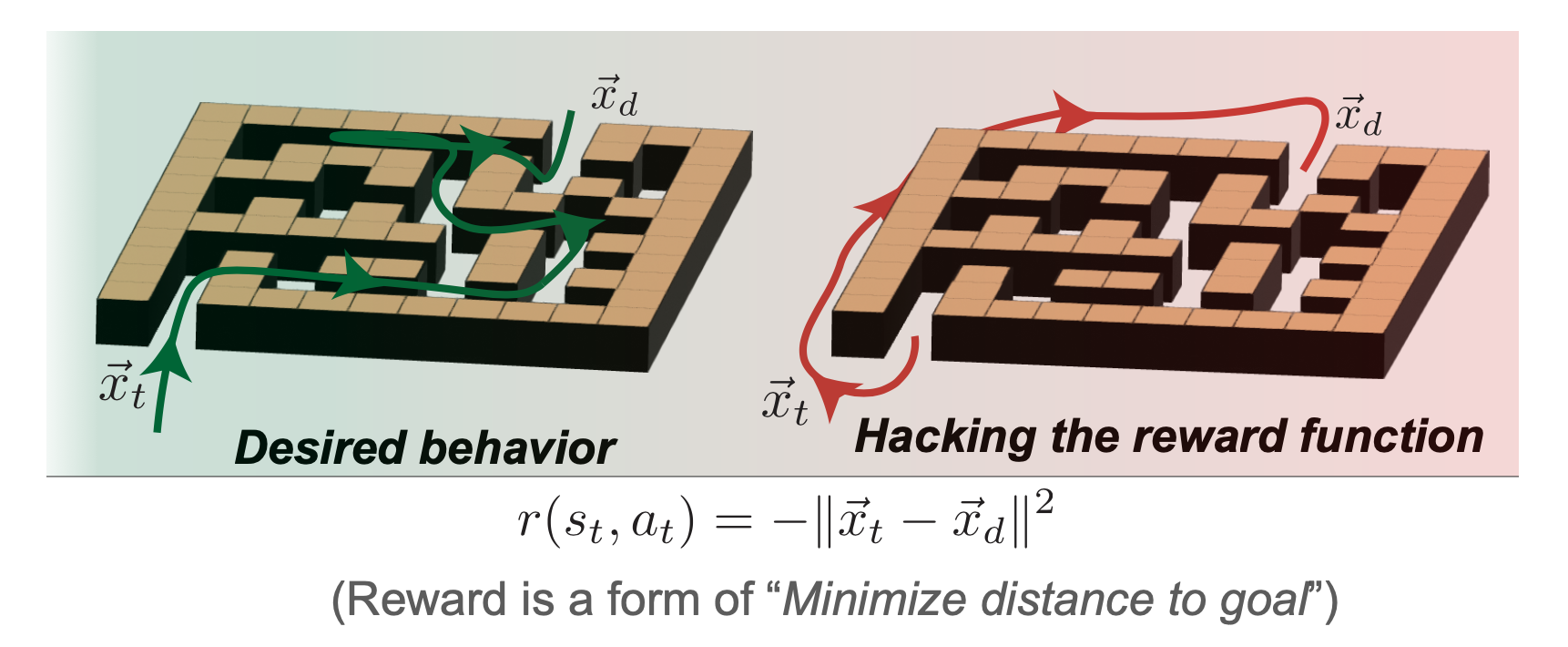
Determine 7: Defining rewards instance with maze navigation.
Pruning Info
A standard observe in RL analysis is to redefine the surroundings to suit one’s wants – RL designers make quite a few specific and implicit assumptions to mannequin duties in a means that makes them amenable to digital RL brokers. In extremely structured domains, reminiscent of video video games, this may be fairly benign.Nevertheless, in the actual world redefining the surroundings quantities to altering the methods data can circulation between the world and the RL agent. This could dramatically change the that means of the reward operate and offload threat to exterior programs. For instance, an autonomous automobile with sensors targeted solely on the street floor shifts the burden from AV designers to pedestrians. On this case, the designer is pruning out details about the encompassing surroundings that’s really essential to robustly secure integration inside society.
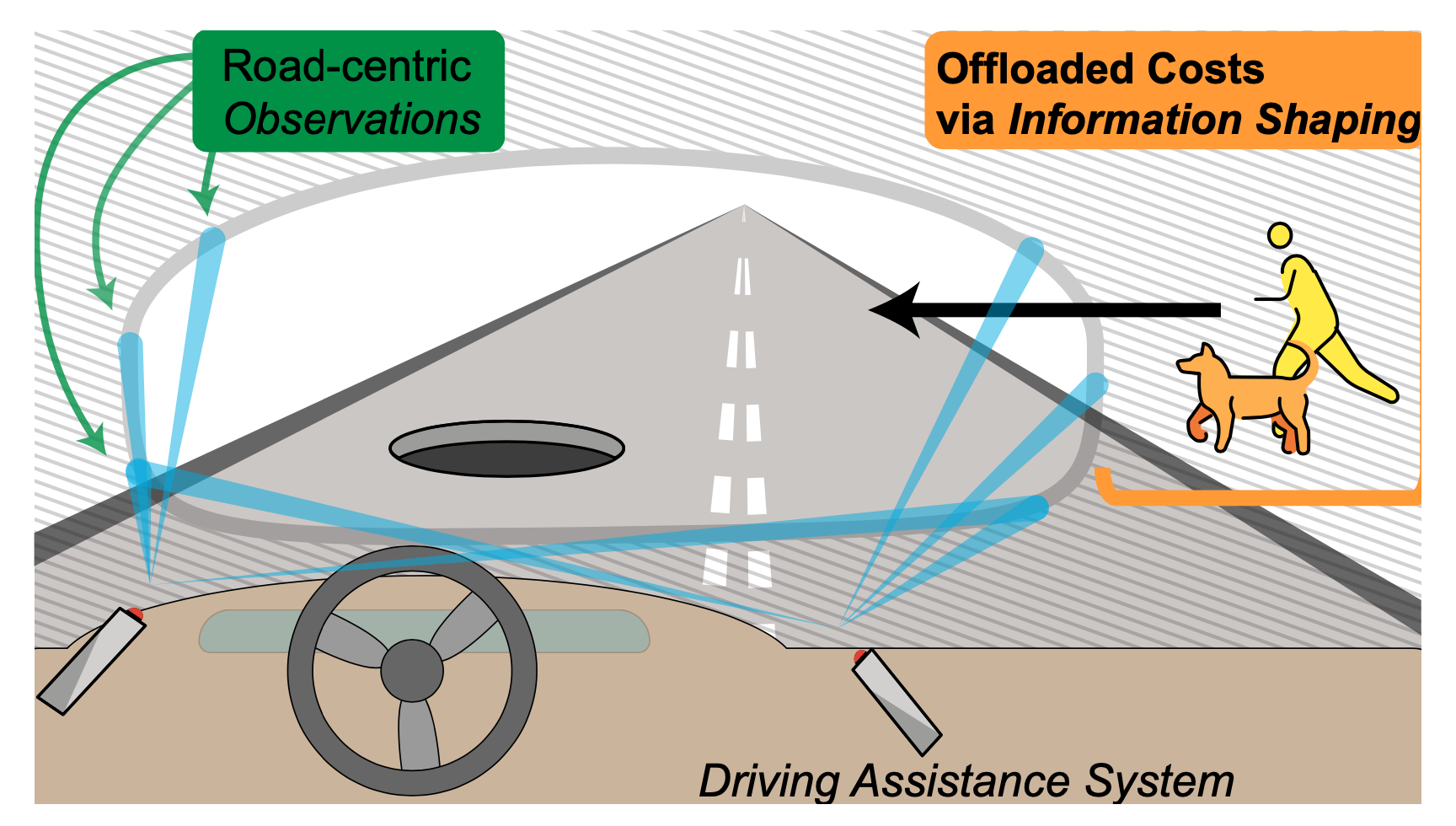
Determine 8: Info shaping instance with an autonomous automobile.
Coaching A number of Brokers
There may be rising curiosity in the issue of multi-agent RL, however as an rising analysis space, little is understood about how studying programs work together inside dynamic environments. When the relative focus of autonomous brokers will increase inside an surroundings, the phrases these brokers optimize for can really re-wire norms and values encoded in that particular software area. An instance could be the modifications in conduct that can come if the vast majority of autos are autonomous and speaking (or not) with one another. On this case, if the brokers have autonomy to optimize towards a purpose of minimizing transit time (for instance), they may crowd out the remaining human drivers and closely disrupt accepted societal norms of transit.
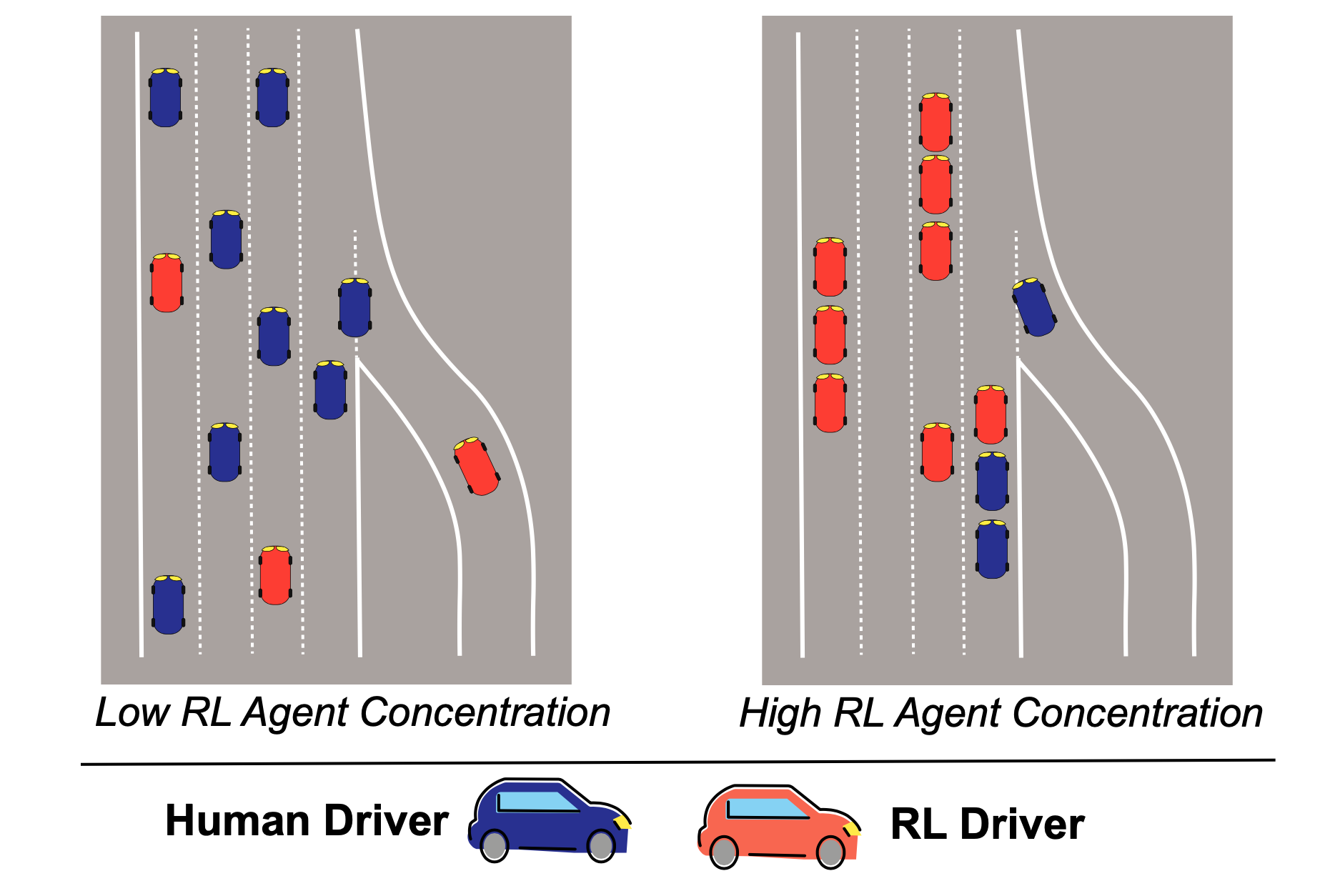
Determine 9: The dangers of multi-agency instance on autonomous autos.
In our current whitepaper and analysis paper, we proposed Reward Experiences, a brand new type of ML documentation that foregrounds the societal dangers posed by sequential data-driven optimization programs, whether or not explicitly constructed as an RL agent or implicitly construed by way of data-driven optimization and suggestions. Constructing on proposals to doc datasets and fashions, we deal with reward capabilities: the target that guides optimization selections in feedback-laden programs. Reward Experiences comprise questions that spotlight the guarantees and dangers entailed in defining what’s being optimized in an AI system, and are supposed as residing paperwork that dissolve the excellence between ex-ante (design) specification and ex-post (after the actual fact) hurt. Because of this, Reward Experiences present a framework for ongoing deliberation and accountability earlier than and after a system is deployed.
Our proposed template for a Reward Experiences consists of a number of sections, organized to assist the reporter themselves perceive and doc the system. A Reward Report begins with (1) system particulars that comprise the knowledge context for deploying the mannequin. From there, the report paperwork (2) the optimization intent, which questions the objectives of the system and why RL or ML could also be a great tool. The designer then paperwork (3) how the system might have an effect on totally different stakeholders within the institutional interface. The following two sections comprise technical particulars on (4) the system implementation and (5) analysis. Reward stories conclude with (6) plans for system upkeep as extra system dynamics are uncovered.
Crucial function of a Reward Report is that it permits documentation to evolve over time, in line with the temporal evolution of an internet, deployed RL system! That is most evident within the change-log, which is we find on the finish of our Reward Report template:

Determine 10: Reward Experiences contents.
What would this seem like in observe?
As a part of our analysis, we’ve got developed a reward report LaTeX template, in addition to a number of instance reward stories that purpose for instance the sorts of points that might be managed by this type of documentation. These examples embrace the temporal evolution of the MovieLens recommender system, the DeepMind MuZero recreation taking part in system, and a hypothetical deployment of an RL autonomous automobile coverage for managing merging visitors, based mostly on the Mission Circulation simulator.
Nevertheless, these are simply examples that we hope will serve to encourage the RL group–as extra RL programs are deployed in real-world functions, we hope the analysis group will construct on our concepts for Reward Experiences and refine the precise content material that needs to be included. To this finish, we hope that you’ll be a part of us at our (un)-workshop.
Work with us on Reward Experiences: An (Un)Workshop!
We’re internet hosting an “un-workshop” on the upcoming convention on Reinforcement Studying and Choice Making (RLDM) on June eleventh from 1:00-5:00pm EST at Brown College, Windfall, RI. We name this an un-workshop as a result of we’re in search of the attendees to assist create the content material! We are going to present templates, concepts, and dialogue as our attendees construct out instance stories. We’re excited to develop the concepts behind Reward Experiences with real-world practitioners and cutting-edge researchers.
For extra data on the workshop, go to the web site or contact the organizers at geese-org@lists.berkeley.edu.
This submit relies on the next papers:
{kind=link}