

A protracted-standing drawback within the intersection of pc imaginative and prescient and pc graphics, view synthesis is the duty of making new views of a scene from a number of footage of that scene. This has obtained elevated consideration [1, 2, 3] since the introduction of neural radiance fields (NeRF). The issue is difficult as a result of to precisely synthesize new views of a scene, a mannequin must seize many sorts of info — its detailed 3D construction, supplies, and illumination — from a small set of reference photographs.
On this publish, we current lately printed deep studying fashions for view synthesis. In “Gentle Subject Neural Rendering” (LFNR), introduced at CVPR 2022, we tackle the problem of precisely reproducing view-dependent results by utilizing transformers that study to mix reference pixel colours. Then in “Generalizable Patch-Based mostly Neural Rendering” (GPNR), to be introduced at ECCV 2022, we tackle the problem of generalizing to unseen scenes by utilizing a sequence of transformers with canonicalized positional encoding that may be educated on a set of scenes to synthesize views of recent scenes. These fashions have some distinctive options. They carry out image-based rendering, combining colours and options from the reference photographs to render novel views. They’re purely transformer-based, working on units of picture patches, and so they leverage a 4D mild subject illustration for positional encoding, which helps to mannequin view-dependent results.
 |
 |
| We prepare deep studying fashions which can be in a position to produce new views of a scene given a couple of photographs of it. These fashions are significantly efficient when dealing with view-dependent results just like the refractions and translucency on the check tubes. This animation is compressed; see the original-quality renderings right here. Supply: Lab scene from the NeX/Shiny dataset. |
Overview
The enter to the fashions consists of a set of reference photographs and their digicam parameters (focal size, place, and orientation in house), together with the coordinates of the goal ray whose coloration we need to decide. To provide a brand new picture, we begin from the digicam parameters of the enter photographs, get hold of the coordinates of the goal rays (every equivalent to a pixel), and question the mannequin for every.
As a substitute of processing every reference picture utterly, we glance solely on the areas which can be prone to affect the goal pixel. These areas are decided by way of epipolar geometry, which maps every goal pixel to a line on every reference body. For robustness, we take small areas round various factors on the epipolar line, ensuing within the set of patches that can really be processed by the mannequin. The transformers then act on this set of patches to acquire the colour of the goal pixel.
Transformers are particularly helpful on this setting since their self-attention mechanism naturally takes units as inputs, and the eye weights themselves can be utilized to mix reference view colours and options to foretell the output pixel colours. These transformers observe the structure launched in ViT.
 |
| To foretell the colour of 1 pixel, the fashions take a set of patches extracted across the epipolar line of every reference view. Picture supply: LLFF dataset. |
Gentle Subject Neural Rendering
In Gentle Subject Neural Rendering (LFNR), we use a sequence of two transformers to map the set of patches to the goal pixel coloration. The primary transformer aggregates info alongside every epipolar line, and the second alongside every reference picture. We are able to interpret the primary transformer as discovering potential correspondences of the goal pixel on every reference body, and the second as reasoning about occlusion and view-dependent results, that are widespread challenges of image-based rendering.
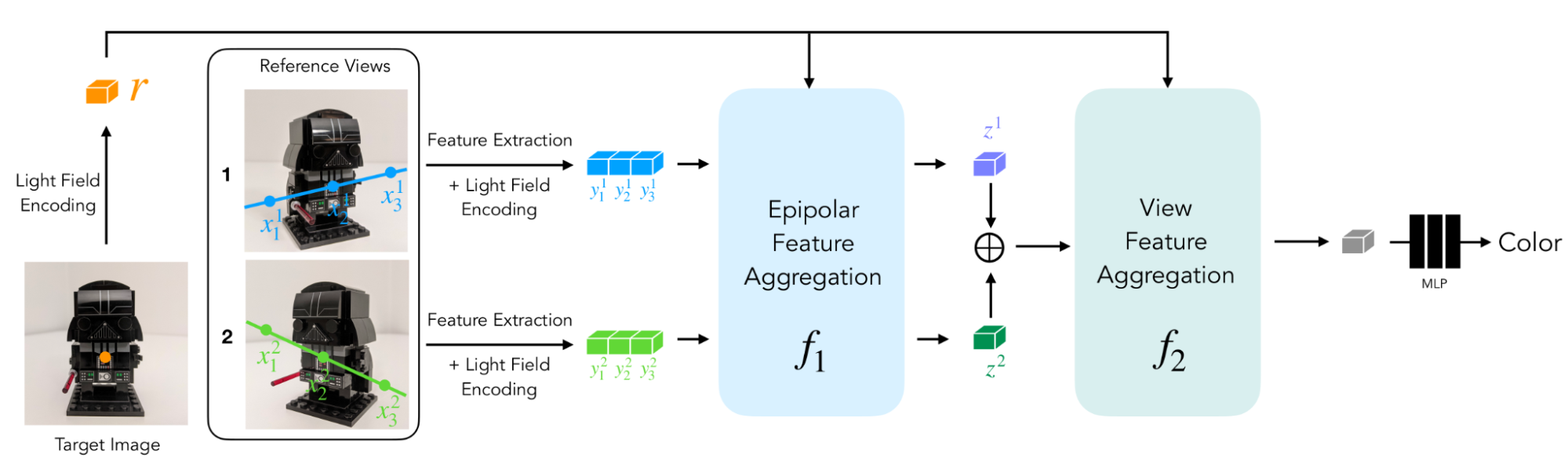 |
| LFNR makes use of a sequence of two transformers to map a set of patches extracted alongside epipolar traces to the goal pixel coloration. |
LFNR improved the state-of-the-art on the most well-liked view synthesis benchmarks (Blender and Actual Ahead-Going through scenes from NeRF and Shiny from NeX) with margins as massive as 5dB peak signal-to-noise ratio (PSNR). This corresponds to a discount of the pixel-wise error by an element of 1.8x. We present qualitative outcomes on difficult scenes from the Shiny dataset under:
 |
| LFNR reproduces difficult view-dependent results just like the rainbow and reflections on the CD, reflections, refractions and translucency on the bottles. This animation is compressed; see the unique high quality renderings right here. Supply: CD scene from the NeX/Shiny dataset. |
 |
| Prior strategies resembling NeX and NeRF fail to breed view-dependent results just like the translucency and refractions within the check tubes on the Lab scene from the NeX/Shiny dataset. See additionally our video of this scene on the prime of the publish and the unique high quality outputs right here. |
Generalizing to New Scenes
One limitation of LFNR is that the primary transformer collapses the knowledge alongside every epipolar line independently for every reference picture. Because of this it decides which info to protect based mostly solely on the output ray coordinates and patches from every reference picture, which works effectively when coaching on a single scene (as most neural rendering strategies do), but it surely doesn’t generalize throughout scenes. Generalizable strategies are vital as a result of they are often utilized to new scenes while not having to retrain.
We overcome this limitation of LFNR in Generalizable Patch-Based mostly Neural Rendering (GPNR). We add a transformer that runs earlier than the opposite two and exchanges info between factors on the similar depth over all reference photographs. For instance, this primary transformer appears on the columns of the patches from the park bench proven above and might use cues just like the flower that seems at corresponding depths in two views, which signifies a possible match. One other key thought of this work is to canonicalize the positional encoding based mostly on the goal ray, as a result of to generalize throughout scenes, it’s essential to characterize portions in relative and never absolute frames of reference. The animation under exhibits an summary of the mannequin.
 |
| GPNR consists of a sequence of three transformers that map a set of patches extracted alongside epipolar traces to a pixel coloration. Picture patches are mapped by way of the linear projection layer to preliminary options (proven as blue and inexperienced bins). Then these options are successively refined and aggregated by the mannequin, ensuing within the last characteristic/coloration represented by the grey rectangle. Park bench picture supply: LLFF dataset. |
To guage the generalization efficiency, we prepare GPNR on a set of scenes and check it on new scenes. GPNR improved the state-of-the-art on a number of benchmarks (following IBRNet and MVSNeRF protocols) by 0.5–1.0 dB on common. On the IBRNet benchmark, GPNR outperforms the baselines whereas utilizing solely 11% of the coaching scenes. The outcomes under present new views of unseen scenes rendered with no fine-tuning.
 |
| GPNR-generated views of held-out scenes, with none positive tuning. This animation is compressed; see the unique high quality renderings right here. Supply: IBRNet collected dataset. |
 |
| Particulars of GPNR-generated views on held-out scenes from NeX/Shiny (left) and LLFF (proper), with none positive tuning. GPNR reproduces extra precisely the main points on the leaf and the refractions by means of the lens in comparison in opposition to IBRNet. |
Future Work
One limitation of most neural rendering strategies, together with ours, is that they require digicam poses for every enter picture. Poses will not be straightforward to acquire and usually come from offline optimization strategies that may be gradual, limiting attainable purposes, resembling these on cellular gadgets. Analysis on collectively studying view synthesis and enter poses is a promising future course. One other limitation of our fashions is that they’re computationally costly to coach. There’s an lively line of analysis on quicker transformers which could assist enhance our fashions’ effectivity. For the papers, extra outcomes, and open-source code, you possibly can try the tasks pages for “Gentle Subject Neural Rendering” and “Generalizable Patch-Based mostly Neural Rendering“.
Potential Misuse
In our analysis, we intention to precisely reproduce an present scene utilizing photographs from that scene, so there may be little room to generate pretend or non-existing scenes. Our fashions assume static scenes, so synthesizing shifting objects, resembling folks, won’t work.
Acknowledgments
All of the laborious work was executed by our wonderful intern – Mohammed Suhail – a PhD pupil at UBC, in collaboration with Carlos Esteves and Ameesh Makadia from Google Analysis, and Leonid Sigal from UBC. We’re grateful to Corinna Cortes for supporting and inspiring this challenge.
Our work is impressed by NeRF, which sparked the current curiosity in view synthesis, and IBRNet, which first thought-about generalization to new scenes. Our mild ray positional encoding is impressed by the seminal paper Gentle Subject Rendering and our use of transformers observe ViT.
Video outcomes are from scenes from LLFF, Shiny, and IBRNet collected datasets.
{kind=link}