
Clustering is a central drawback in unsupervised machine studying (ML) with many functions throughout domains in each trade and educational analysis extra broadly. At its core, clustering consists of the next drawback: given a set of information parts, the aim is to partition the info parts into teams such that comparable objects are in the identical group, whereas dissimilar objects are in numerous teams. This drawback has been studied in math, laptop science, operations analysis and statistics for greater than 60 years in its myriad variants. Two frequent types of clustering are metric clustering, through which the weather are factors in a metric house, like within the k-means drawback, and graph clustering, the place the weather are nodes of a graph whose edges symbolize similarity amongst them.
 |
| Within the k-means clustering drawback, we’re given a set of factors in a metric house with the target to establish ok consultant factors, referred to as facilities (right here depicted as triangles), in order to attenuate the sum of the squared distances from every level to its closest heart. Supply, rights: CC-BY-SA-4.0 |
{kind=link}
Regardless of the intensive literature on algorithm design for clustering, few sensible works have targeted on rigorously defending the person’s privateness throughout clustering. When clustering is utilized to non-public knowledge (e.g., the queries a person has made), it’s crucial to contemplate the privateness implications of utilizing a clustering answer in an actual system and the way a lot data the output answer reveals concerning the enter knowledge.
To make sure privateness in a rigorous sense, one answer is to develop differentially personal (DP) clustering algorithms. These algorithms be sure that the output of the clustering doesn’t reveal personal details about a selected knowledge component (e.g., whether or not a person has made a given question) or delicate knowledge concerning the enter graph (e.g., a relationship in a social community). Given the significance of privateness protections in unsupervised machine studying, lately Google has invested in analysis on concept and apply of differentially personal metric or graph clustering, and differential privateness in quite a lot of contexts, e.g., heatmaps or instruments to design DP algorithms.
Right this moment we’re excited to announce two vital updates: 1) a new differentially-private algorithm for hierarchical graph clustering, which we’ll be presenting at ICML 2023, and a pair of) the open-source launch of the code of a scalable differentially-private ok-means algorithm. This code brings differentially personal ok-means clustering to giant scale datasets utilizing distributed computing. Right here, we will even talk about our work on clustering know-how for a current launch within the well being area for informing public well being authorities.
Differentially personal hierarchical clustering
Hierarchical clustering is a well-liked clustering method that consists of recursively partitioning a dataset into clusters at an more and more finer granularity. A well-known instance of hierarchical clustering is the phylogenetic tree in biology through which all life on Earth is partitioned into finer and finer teams (e.g., kingdom, phylum, class, order, and many others.). A hierarchical clustering algorithm receives as enter a graph representing the similarity of entities and learns such recursive partitions in an unsupervised manner. But on the time of our analysis no algorithm was identified to compute hierarchical clustering of a graph with edge privateness, i.e., preserving the privateness of the vertex interactions.
In “Differentially-Personal Hierarchical Clustering with Provable Approximation Ensures”, we think about how effectively the issue will be approximated in a DP context and set up agency higher and decrease bounds on the privateness assure. We design an approximation algorithm (the primary of its variety) with a polynomial operating time that achieves each an additive error that scales with the variety of nodes n (of order n2.5) and a multiplicative approximation of O(log½ n), with the multiplicative error an identical to the non-private setting. We additional present a brand new decrease certain on the additive error (of order n2) for any personal algorithm (regardless of its operating time) and supply an exponential-time algorithm that matches this decrease certain. Furthermore, our paper features a beyond-worst-case evaluation specializing in the hierarchical stochastic block mannequin, a regular random graph mannequin that reveals a pure hierarchical clustering construction, and introduces a non-public algorithm that returns an answer with an additive value over the optimum that’s negligible for bigger and bigger graphs, once more matching the non-private state-of-the-art approaches. We imagine this work expands the understanding of privateness preserving algorithms on graph knowledge and can allow new functions in such settings.
Massive-scale differentially personal clustering
We now swap gears and talk about our work for metric house clustering. Most prior work in DP metric clustering has targeted on bettering the approximation ensures of the algorithms on the ok-means goal, leaving scalability questions out of the image. Certainly, it’s not clear how environment friendly non-private algorithms similar to k-means++ or k-means// will be made differentially personal with out sacrificing drastically both on the approximation ensures or the scalability. Alternatively, each scalability and privateness are of major significance at Google. Because of this, we not too long ago printed a number of papers that deal with the issue of designing environment friendly differentially personal algorithms for clustering that may scale to huge datasets. Our aim is, furthermore, to supply scalability to giant scale enter datasets, even when the goal variety of facilities, ok, is giant.
We work within the massively parallel computation (MPC) mannequin, which is a computation mannequin consultant of contemporary distributed computation architectures. The mannequin consists of a number of machines, every holding solely a part of the enter knowledge, that work along with the aim of fixing a worldwide drawback whereas minimizing the quantity of communication between machines. We current a differentially personal fixed issue approximation algorithm for ok-means that solely requires a continuing variety of rounds of synchronization. Our algorithm builds upon our earlier work on the issue (with code accessible right here), which was the primary differentially-private clustering algorithm with provable approximation ensures that may work within the MPC mannequin.
The DP fixed issue approximation algorithm drastically improves on the earlier work utilizing a two part method. In an preliminary part it computes a crude approximation to “seed” the second part, which consists of a extra refined distributed algorithm. Geared up with the first-step approximation, the second part depends on outcomes from the Coreset literature to subsample a related set of enter factors and discover a good differentially personal clustering answer for the enter factors. We then show that this answer generalizes with roughly the identical assure to your entire enter.
Vaccination search insights through DP clustering
We then apply these advances in differentially personal clustering to real-world functions. One instance is our software of our differentially-private clustering answer for publishing COVID vaccine-related queries, whereas offering sturdy privateness protections for the customers.
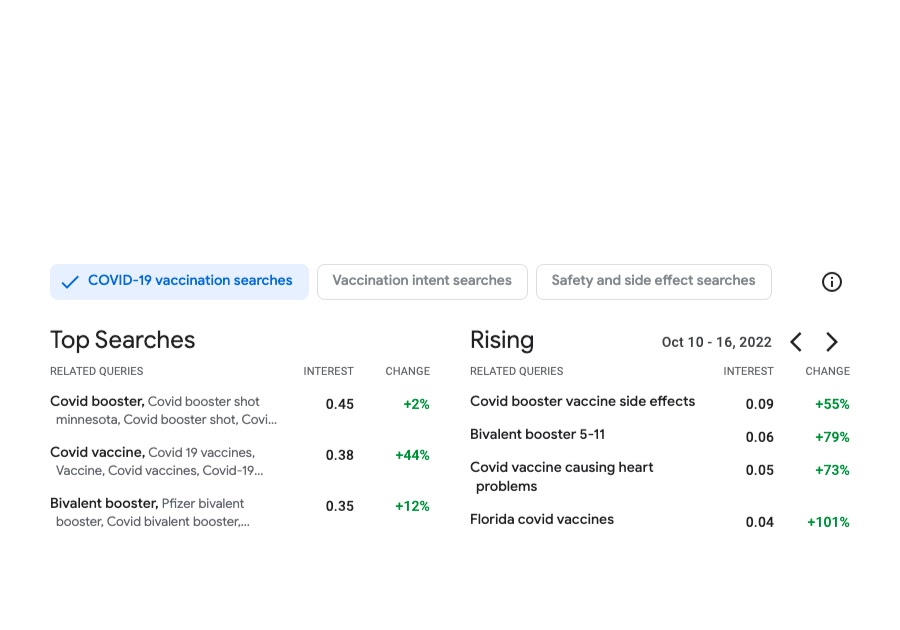
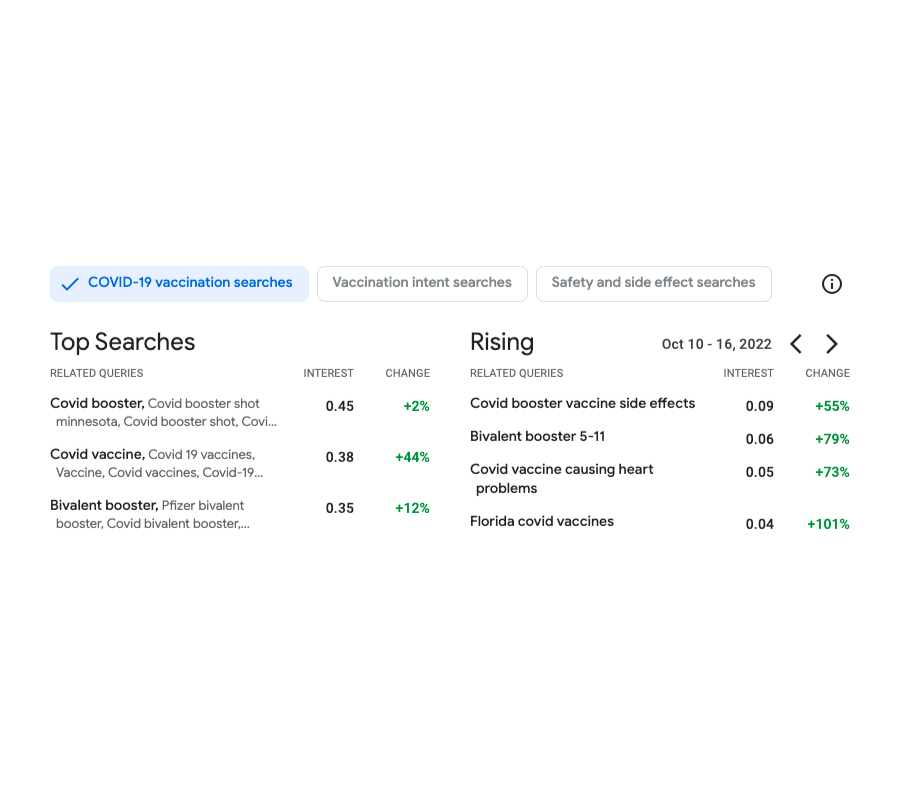
The aim of Vaccination Search Insights (VSI) is to assist public well being resolution makers (well being authorities, authorities companies and nonprofits) establish and reply to communities’ data wants concerning COVID vaccines. To be able to obtain this, the device permits customers to discover at totally different geolocation granularities (zip-code, county and state stage within the U.S.) the highest themes searched by customers concerning COVID queries. Specifically, the device visualizes statistics on trending queries rising in curiosity in a given locale and time.
 |
| Screenshot of the output of the device. Displayed on the left, the highest searches associated to Covid vaccines in the course of the interval Oct 10-16 2022. On the correct, the queries which have had rising significance throughout the identical interval and in comparison with the earlier week. |
To higher assist figuring out the themes of the trending searches, the device clusters the search queries based mostly on their semantic similarity. That is completed by making use of a custom-designed ok-means–based mostly algorithm run over search knowledge that has been anonymized utilizing the DP Gaussian mechanism so as to add noise and take away low-count queries (thus leading to a differentially clustering). The strategy ensures sturdy differential privateness ensures for the safety of the person knowledge.
This device offered fine-grained knowledge on COVID vaccine notion within the inhabitants at unprecedented scales of granularity, one thing that’s particularly related to grasp the wants of the marginalized communities disproportionately affected by COVID. This undertaking highlights the impression of our funding in analysis in differential privateness, and unsupervised ML strategies. We want to different vital areas the place we will apply these clustering strategies to assist information resolution making round international well being challenges, like search queries on local weather change–associated challenges similar to air high quality or excessive warmth.
Acknowledgements
We thank our co-authors Silvio Lattanzi, Vahab Mirrokni, Andres Munoz Medina, Shyam Narayanan, David Saulpic, Chris Schwiegelshohn, Sergei Vassilvitskii, Peilin Zhong and our colleagues from the Well being AI staff that made the VSI launch potential Shailesh Bavadekar, Adam Boulanger, Tague Griffith, Mansi Kansal, Chaitanya Kamath, Akim Kumok, Yael Mayer, Tomer Shekel, Megan Shum, Charlotte Stanton, Mimi Solar, Swapnil Vispute, and Mark Younger.
For extra data on the Graph Mining staff (a part of Algorithm and Optimization) go to our pages.
{kind=link}