
Differential privateness (DP) is an strategy that allows knowledge analytics and machine studying (ML) with a mathematical assure on the privateness of person knowledge. DP quantifies the “privateness price” of an algorithm, i.e., the extent of assure that the algorithm’s output distribution for a given dataset is not going to change considerably if a single person’s knowledge is added to or faraway from it. The algorithm is characterised by two parameters, ε and δ, the place smaller values of each point out “extra non-public”. There’s a pure pressure between the privateness price range (ε, δ) and the utility of the algorithm: a smaller privateness price range requires the output to be extra “noisy”, typically resulting in much less utility. Thus, a basic aim of DP is to achieve as a lot utility as attainable for a desired privateness price range.
A key property of DP that always performs a central function in understanding privateness prices is that of composition, which displays the online privateness price of a mixture of DP algorithms, seen collectively as a single algorithm. A notable instance is the differentially-private stochastic gradient descent (DP-SGD) algorithm. This algorithm trains ML fashions over a number of iterations — every of which is differentially non-public — and subsequently requires an software of the composition property of DP. A fundamental composition theorem in DP says that the privateness price of a group of algorithms is, at most, the sum of the privateness price of every. Nonetheless, in lots of instances, this is usually a gross overestimate, and several other improved composition theorems present higher estimates of the privateness price of composition.
In 2019, we launched an open-source library (on GitHub) to allow builders to make use of analytic methods primarily based on DP. At present, we announce the addition to this library of Join-the-Dots, a brand new privateness accounting algorithm primarily based on a novel strategy for discretizing privateness loss distributions that could be a useful gizmo for understanding the privateness price of composition. This algorithm relies on the paper “Join the Dots: Tighter Discrete Approximations of Privateness Loss Distributions”, introduced at PETS 2022. The principle novelty of this accounting algorithm is that it makes use of an oblique strategy to assemble extra correct discretizations of privateness loss distributions. We discover that Join-the-Dots offers vital good points over different privateness accounting strategies in literature when it comes to accuracy and working time. This algorithm was additionally just lately utilized for the privateness accounting of DP-SGD in coaching Advertisements prediction fashions.
Differential Privateness and Privateness Loss Distributions
A randomized algorithm is claimed to fulfill DP ensures if its output “doesn’t rely considerably” on anyone entry in its coaching dataset, quantified mathematically with parameters (ε, δ). For instance, take into account the motivating instance of DP-SGD. When educated with (non-private) SGD, a neural community might, in precept, be encoding your entire coaching dataset inside its weights, thereby permitting one to reconstruct some coaching examples from a educated mannequin. However, when educated with DP-SGD, we now have a proper assure that if one had been in a position to reconstruct a coaching instance with non-trivial likelihood then one would additionally be capable of reconstruct the identical instance even when it was not included within the coaching dataset.
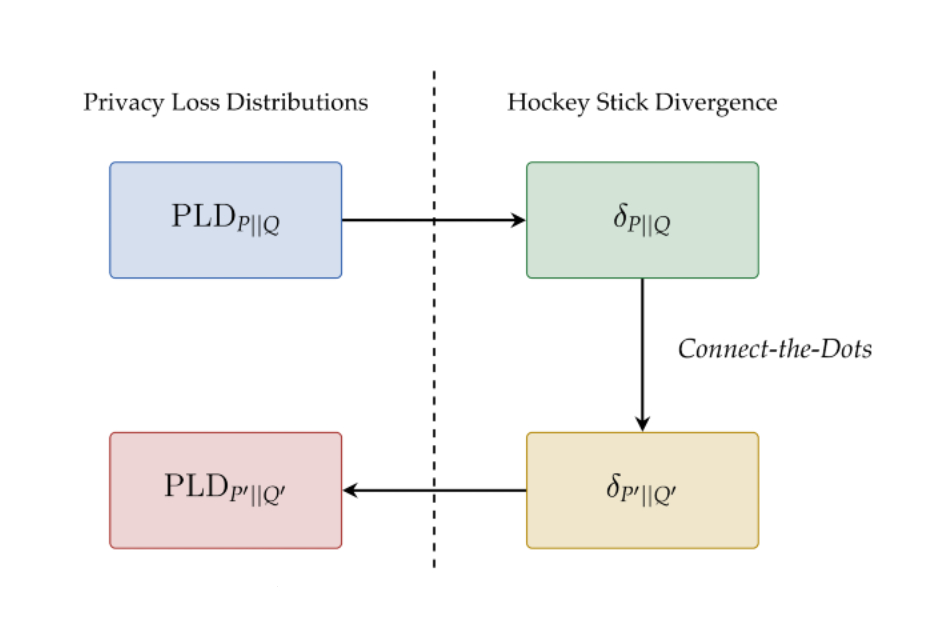
The hockey stick divergence, parameterized by ε, is a measure of distance between two likelihood distributions, as illustrated within the determine under. The privateness price of most DP algorithms is dictated by the hockey stick divergence between two related likelihood distributions P and Q. The algorithm satisfies DP with parameters (ε, δ), if the worth of the hockey stick divergence for ε between P and Q is at most δ. The hockey stick divergence between (P, Q), denoted δP||Q(ε) is in flip utterly characterised by it related privateness loss distribution, denoted by PLDP||Q.
 |
| Illustration of hockey stick divergence δP||Q(ε) between distributions P and Q (left), which corresponds to the likelihood mass of P that’s above eεQ, the place eεQ is an eε scaling of the likelihood mass of Q (proper). |
The principle benefit of coping with PLDs is that compositions of algorithms correspond to the convolution of the corresponding PLDs. Exploiting this truth, prior work has designed environment friendly algorithms to compute the PLD equivalent to the composition of particular person algorithms by merely performing convolution of the person PLDs utilizing the quick Fourier remodel algorithm.
Nonetheless, one problem when coping with many PLDs is that they typically are steady distributions, which make the convolution operations intractable in observe. Thus, researchers typically apply numerous discretization approaches to approximate the PLDs utilizing equally spaced factors. For instance, the fundamental model of the Privateness Buckets algorithm assigns the likelihood mass of the interval between two discretization factors totally to the upper finish of the interval.
 |
| Illustration of discretization by rounding up likelihood lots. Right here a steady PLD (in blue) is discretized to a discrete PLD (in purple), by rounding up the likelihood mass between consecutive factors. |
Join-the-Dots : A New Algorithm
Our new Join-the-Dots algorithm offers a greater solution to discretize PLDs in the direction of the aim of estimating hockey stick divergences. This strategy works not directly by first discretizing the hockey stick divergence perform after which mapping it again to a discrete PLD supported on equally spaced factors.
 |
| Illustration of high-level steps within the Join-the-Dots algorithm. |
This strategy depends on the notion of a “dominating PLD”, particularly, PLDP’||Q’ dominates over PLDP||Q if the hockey stick divergence of the previous is larger or equal to the hockey stick divergence of the latter for all values of ε. The important thing property of dominating PLDs is that they continue to be dominating after compositions. Thus for functions of privateness accounting, it suffices to work with a dominating PLD, which provides us an higher sure on the precise privateness price.
Our essential perception behind the Join-the-Dots algorithm is a characterization of discrete PLD, particularly {that a} PLD is supported on a given finite set of ε values if and provided that the corresponding hockey stick divergence as a perform of eε is linear between consecutive eε values. This enables us to discretize the hockey stick divergence by merely connecting the dots to get a piecewise linear perform that exactly equals the hockey stick divergence perform on the given eε values. See a extra detailed clarification of the algorithm.
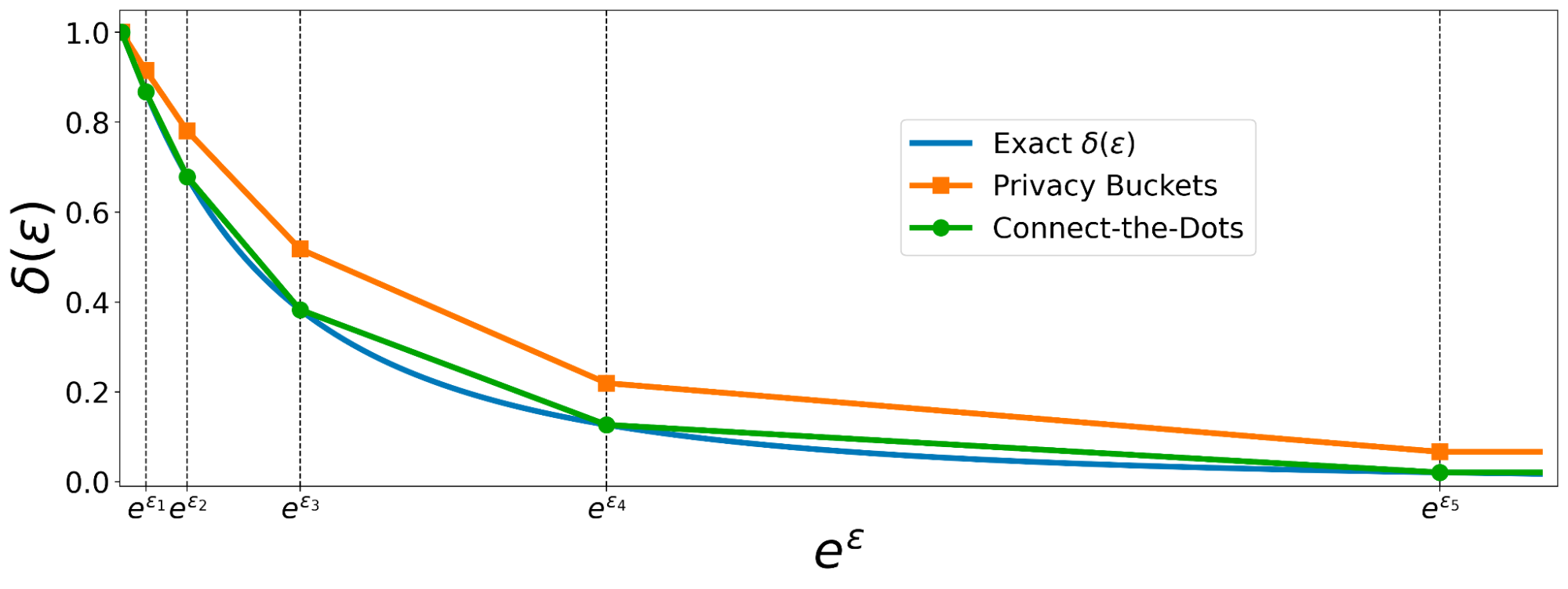 |
| Comparability of the discretizations of hockey stick divergence by Join-the-Dots vs Privateness Buckets. |
Experimental Analysis
The DP-SGD algorithm includes a noise multiplier parameter, which controls the magnitude of noise added in every gradient step, and a sampling likelihood, which controls what number of examples are included in every mini-batch. We evaluate Join-the-Dots in opposition to the algorithms listed under on the duty of privateness accounting DP-SGD with a noise multiplier = 0.5, sampling likelihood = 0.2 x 10-4 and δ = 10-8.
We plot the worth of the ε computed by every of the algorithms in opposition to the variety of composition steps, and moreover, we plot the working time of the implementations. As proven within the plots under, privateness accounting utilizing Renyi DP offers a unfastened estimate of the privateness loss. Nonetheless, when evaluating the approaches utilizing PLD, we discover that on this instance, the implementation of Join-the-Dots achieves a tighter estimate of the privateness loss, with a working time that’s 5x sooner than the Microsoft PRV Accountant and >200x sooner than the earlier strategy of Privateness Buckets within the Google-DP library.
 |
| Left: Higher bounds on the privateness parameter ε for various variety of steps of DP-SGD, as returned by totally different algorithms (for fastened δ = 10-8). Proper: Working time of the totally different algorithms. |
Conclusion & Future Instructions
This work proposes Join-the-Dots, a brand new algorithm for computing optimum privateness parameters for compositions of differentially non-public algorithms. When evaluated on the DP-SGD job, we discover that this algorithm provides tighter estimates on the privateness loss with a considerably sooner working time.
To date, the library solely helps the pessimistic estimate model of Join-the-Dots algorithm, which offers an higher sure on the privateness lack of DP-algorithms. Nonetheless, the paper additionally introduces a variant of the algorithm that gives an “optimistic” estimate of the PLD, which can be utilized to derive decrease bounds on the privateness price of DP-algorithms (supplied these admit a “worst case” PLD). At present, the library does assist optimistic estimates as given by the Privateness Buckets algorithm, and we hope to include the Join-the-Dots model as nicely.
Acknowledgements
This work was carried out in collaboration with Vadym Doroshenko, Badih Ghazi, Ravi Kumar. We thank Galen Andrew, Stan Bashtavenko, Steve Chien, Christoph Dibak, Miguel Guevara, Peter Kairouz, Sasha Kulankhina, Stefan Mellem, Jodi Spacek, Yurii Sushko and Andreas Terzis for his or her assist.
{kind=link}