

Construction prediction is a elementary downside in molecular science as a result of the construction of a molecule determines its properties and capabilities. In recent times, deep studying strategies have made outstanding progress and influence on predicting molecular constructions, particularly for protein molecules. Deep studying strategies, equivalent to AlphaFold and RoseTTAFold, have achieved unprecedented accuracy in predicting essentially the most possible constructions for proteins from their amino acid sequences and have been hailed as a sport changer in molecular science. Nevertheless, this methodology offers solely a single snapshot of a protein construction, and construction prediction can not inform the whole story of how a molecule works.
Proteins will not be inflexible objects; they’re dynamic molecules that may undertake totally different constructions with particular possibilities at equilibrium. Figuring out these constructions and their possibilities is crucial in understanding protein properties and capabilities, how they work together with different proteins, and the statistical mechanics and thermodynamics of molecular programs. Conventional strategies for acquiring these equilibrium distributions, equivalent to molecular dynamics simulations or Monte Carlo sampling (which makes use of repeated random sampling from a distribution to attain numerical statistical outcomes), are sometimes computationally costly and should even develop into intractable for complicated molecules. Subsequently, there’s a urgent want for novel computational approaches that may precisely and effectively predict the equilibrium distributions of molecular constructions from primary descriptors.
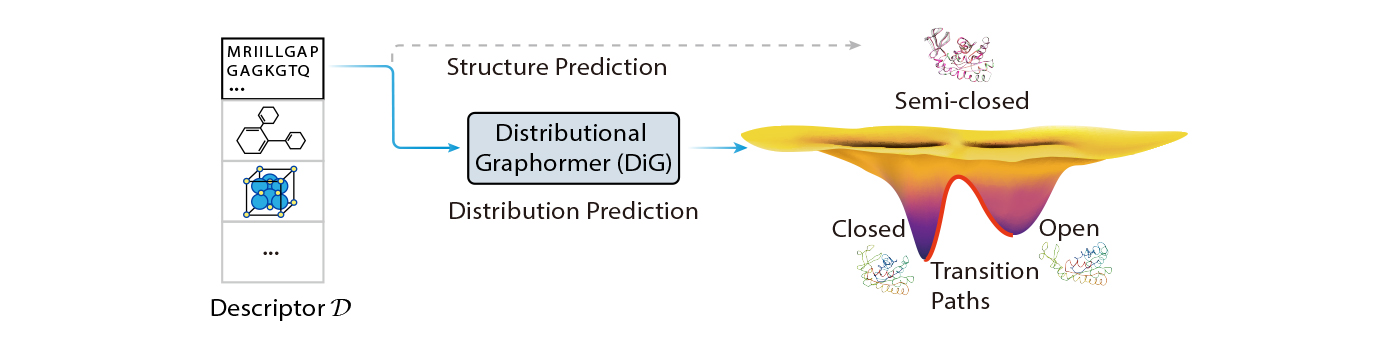
On this weblog submit, we introduce Distributional Graphormer (DiG), a brand new deep studying framework for predicting protein constructions in accordance with their equilibrium distribution. It goals to deal with this elementary problem and open new alternatives for molecular science. DiG is a major development from single construction prediction to construction ensemble modeling with equilibrium distributions. Its distribution prediction functionality bridges the hole between the microscopic constructions and the macroscopic properties of molecular programs, that are ruled by statistical mechanics and thermodynamics. Nonetheless, it is a large problem, because it requires modeling complicated distributions in high-dimensional house to seize the chances of various molecular states.
DiG achieves a novel resolution for distribution prediction by an development of our earlier work, Graphormer, which is a general-purpose graph transformer that may successfully mannequin molecular constructions. Graphormer has proven glorious efficiency in molecular science analysis, demonstrated by purposes in quantum chemistry and molecular dynamics simulations, as reported in our earlier weblog posts (see right here and right here for extra particulars). Now, we’ve got superior Graphormer to create DiG, which has a brand new and highly effective functionality: utilizing deep neural networks to immediately predict goal distribution from primary descriptors of molecules.
Highlight: Microsoft Analysis Podcast
AI Frontiers: AI for well being and the way forward for analysis with Peter Lee
Peter Lee, head of Microsoft Analysis, and Ashley Llorens, AI scientist and engineer, focus on the way forward for AI analysis and the potential for GPT-4 as a medical copilot.
DiG tackles this difficult downside. It’s primarily based on the concept of simulated annealing, a traditional methodology in thermodynamics and optimization, which has additionally motivated the latest improvement of diffusion fashions that achieved outstanding breakthroughs in AI-generated content material (AIGC). Simulated annealing produces a fancy distribution by progressively refining a easy distribution by the simulation of an annealing course of, permitting it to discover and settle in essentially the most possible states. DiG mimics this course of in a deep studying framework for molecular programs. AIGC fashions are sometimes primarily based on the concept of diffusion fashions, that are impressed by statistical mechanics and thermodynamics.
DiG can also be primarily based on the concept of diffusion fashions, however we deliver this concept again to thermodynamics analysis, making a closed loop of inspiration and innovation. We think about scientists sometime will be capable to use DiG like an AIGC mannequin for drawing, inputting a easy description, equivalent to an amino acid sequence, after which utilizing DiG to shortly generate real looking and various protein constructions that comply with equilibrium distribution. It will enormously improve scientists’ productiveness and creativity, enabling novel discoveries and purposes in fields equivalent to drug design, supplies science, and catalysis.
How does DiG work?
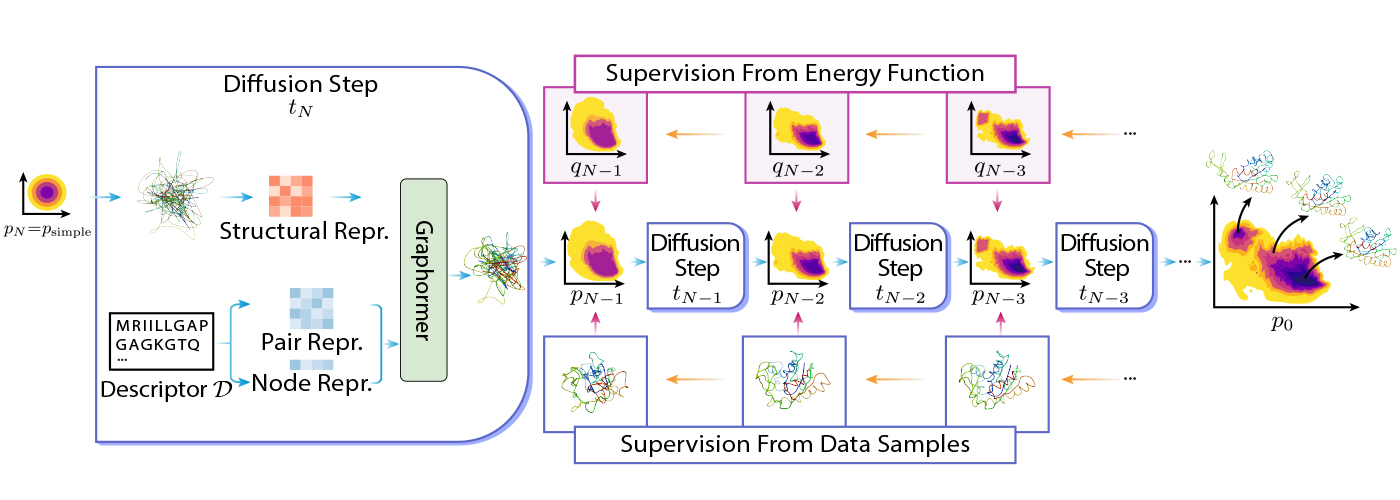
DiG relies on the concept of diffusion by reworking a easy distribution to a fancy distribution utilizing Graphormer. The easy distribution could be a customary Gaussian, and the complicated distribution will be the equilibrium distribution of molecular constructions. The transformation is completed step-by-step, the place the entire course of mimics the simulated annealing course of.
DiG will be educated utilizing several types of knowledge or data. For instance, DiG can use vitality capabilities of molecular programs to information transformation, and it may additionally use simulated construction knowledge, equivalent to molecular dynamics trajectories, to study the distribution. Extra concretely, DiG can use vitality capabilities of molecular programs to information transformation by minimizing the discrepancy between the energy-based possibilities and the chances predicted by DiG. This strategy can leverage the prior data of the system and practice DiG with out stringent dependency on knowledge. Alternatively, DiG may also use simulation knowledge, equivalent to molecular dynamics trajectories, to study the distribution by maximizing the chance of the information below the DiG mannequin.
DiG reveals equally good generalizing talents on many molecular programs in contrast with deep learning-based construction prediction strategies. It is because DiG inherits the benefits of superior deep-learning architectures like Graphormer and applies them to the brand new and difficult process of distribution prediction. As soon as educated, DiG can generate molecular constructions by reversing the transformation course of, ranging from a easy distribution and making use of neural networks in reverse order. DiG may also present the chance estimation for every generated construction by computing the change of chance alongside the transformation course of. DiG is a versatile and common framework that may deal with several types of molecular programs and descriptors.
Outcomes
We display DiG’s efficiency and potential by a number of molecular sampling duties overlaying a broad vary of molecular programs, equivalent to proteins, protein-ligand complexes, and catalyst-adsorbate programs. Our outcomes present that DiG not solely generates real looking and various molecular constructions with excessive effectivity and low computational prices, nevertheless it additionally offers estimations of state densities, that are essential for computing macroscopic properties utilizing statistical mechanics. Accordingly, DiG presents a major development in statistically understanding microscopic molecules and predicting their macroscopic properties, creating many thrilling analysis alternatives in molecular science.
One main software of DiG is to pattern protein conformations, that are indispensable to understanding their properties and capabilities. Proteins are dynamic molecules that may undertake various constructions with totally different possibilities at equilibrium, and these constructions are sometimes associated to their organic capabilities and interactions with different molecules. Nevertheless, predicting the equilibrium distribution of protein conformations is a long-standing and difficult downside because of the complicated and high-dimensional vitality panorama that governs chance distribution within the conformation house. In distinction to costly and inefficient molecular dynamics simulations or Monte Carlo sampling strategies, DiG generates various and functionally related protein constructions from amino acid sequences at a excessive pace and a considerably lowered value.
DiG can generate a number of conformations from the identical protein sequence. The left facet of Determine 3 reveals DiG-generated constructions of the principle protease of SARS-CoV-2 virus in contrast with MD simulations and AlphaFold prediction outcomes. The contours (proven as strains) within the 2D house reveal three clusters sampled by in depth MD simulations. DiG generates extremely comparable constructions in clusters II and III, whereas constructions in cluster I are undersampled. In the precise panel, DiG-generated constructions are aligned to experimental constructions for 4 proteins, every with two distinguishable conformations comparable to distinctive practical states. Within the higher left, the Adenylate kinase protein has open and closed states, each nicely sampled by DiG. Equally, for the drug transport protein LmrP, DiG additionally generates constructions for each states. Right here, observe that the closed state is experimentally decided (within the lower-right nook, with PDB ID 6t1z), whereas the opposite is the AlphaFold predicted mannequin that’s per experimental knowledge. Within the case of human B-Raf kinase, the main structural distinction is localized within the A-loop area and a close-by helix, that are nicely captured by DiG. The D-ribose binding protein has two separated domains, which will be packed into two distinct conformations. DiG completely generated the straight-up conformation, however it’s much less correct in predicting the twisted conformation. Nonetheless, moreover the straight-up conformation, DiG generated some conformations that seem like intermediate states.
One other software of DiG is to pattern catalyst-adsorbate programs, that are central to heterogeneous catalysis. Figuring out energetic adsorption websites and secure adsorbate configurations is essential for understanding and designing catalysts, however it’s also fairly difficult because of the complicated surface-molecular interactions. Conventional strategies, equivalent to density practical principle (DFT) calculations and molecular dynamics simulations, are time-consuming and expensive, particularly for big and sophisticated surfaces. DiG predicts adsorption websites and configurations, in addition to their possibilities, from the substrate and adsorbate descriptors. DiG can deal with numerous kinds of adsorbates, equivalent to single atoms or molecules being adsorbed onto several types of substrates, equivalent to metals or alloys.
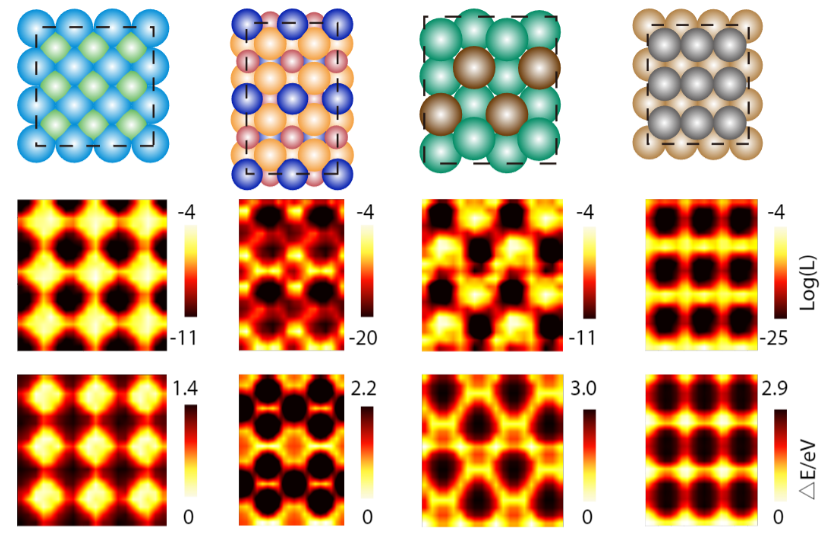
Making use of DiG, we predicted the adsorption websites for quite a lot of catalyst-adsorbate programs and in contrast these predicted possibilities with energies obtained from DFT calculations. We discovered that DiG might discover all of the secure adsorption websites and generate adsorbate configurations which are just like the DFT outcomes with excessive effectivity and at a low value. DiG estimates the chances of various adsorption configurations, in good settlement with DFT energies.
Conclusion
On this weblog, we launched DiG, a deep studying framework that goals to foretell the distribution of molecular constructions. DiG is a major development from single construction prediction towards ensemble modeling with equilibrium distributions, setting a cornerstone for connecting microscopic constructions to macroscopic properties below deep studying frameworks.
DiG entails key ML improvements that result in expressive generative fashions, which have been proven to have the capability to pattern multimodal distribution inside a given class of molecules. We now have demonstrated the pliability of this strategy on totally different lessons of molecules (together with proteins, and many others.), and we’ve got proven that particular person constructions generated on this approach are chemically real looking. Consequently, DiG permits the event of ML programs that may pattern equilibrium distributions of molecules given applicable coaching knowledge.
Nevertheless, we acknowledge that significantly extra analysis is required to acquire environment friendly and dependable predictions of equilibrium distributions for arbitrary molecules. We hope that DiG conjures up further analysis and innovation on this course, and we look ahead to extra thrilling outcomes and influence from DiG and different associated strategies sooner or later.
{kind=link}