


Teleoperation is likely one of the longest-standing utility fields in robotics. Whereas full autonomy continues to be work in progress, the chance to remotely function a robotic has already opened situations the place people can act in dangerous environments with out endangering their very own security, resembling when defusing explosives or decommissioning nuclear waste. It additionally permits one to be current and act even at nice distance: underwater, in area, or inside a affected person miles away from the surgeon. These are all important functions, the place expert and certified operators management the robotic after receiving particular coaching to study to make use of the system safely.
Teleoperation for everybody?
The current pandemic has but made much more obvious the necessity for immersive telepresence and distant motion additionally for non-expert customers: not solely may teleoperated robots take vitals or convey medication to infectious sufferers, however we may help our aged dwelling distant with chores like transferring heavy stuff, or cooking, for instance. Additionally, quite a few bodily jobs might be executed from dwelling.
The current ANA-Xprize finals have proven how far teleoperation can go (see this spectacular video of the profitable staff), however in such conditions each the perceptual and management load lie solely on the operator. This may be fairly taxing on a cognitive degree: each notion and motion are mediated, by cameras and robotic arms respectively, decreasing the person’s scenario consciousness and pure eye-hand coordination. Whereas robotic sensing capabilities and actuators have undergone related technological progress, the interface with the person nonetheless lacks intuitive options facilitating the operator’s job (Rea & Website positioning, 2022).
Human and robotic becoming a member of forces
Shared management has gained recognition in recent times, as an method championing human-machine cooperation: low-level motor management is carried out by the robotic, whereas the human is concentrated on high-level motion planning. To realize such a mix, the robotic system nonetheless wants a well timed option to infer the operator intention, in order to consequently help with the execution. Often, motor intentions are inferred by monitoring arm actions or movement management instructions (if the robotic is operated via a joystick), however particularly throughout object manipulation the hand is tightly following data collected by the gaze. Within the final many years, rising proof in eye-hand coordination research has proven that gaze reliably anticipates the hand motion goal (Hayhoe et al., 2012), offering an early cue about human intention.
Gaze and movement options to estimate intentions
In a contribution introduced at IROS 2022 final month (Belardinelli et al., 2022), we launched an intention estimation mannequin that depends on each gaze and movement options. We collected pick-and-place sequences in a digital surroundings, the place contributors may function two robotic grippers to know objects on a cluttered desk. Movement controllers had been used to trace arm motions and to know objects by button press. Eye actions had been tracked by the eye-tracker embedded within the digital actuality headset.
Gaze options had been computed by defining a Gaussian distribution centered on the gaze place and taking for every object the probability for it to be the goal of visible consideration, which was given by the cumulative distribution collected by the article bounding field. For the movement options, the hand pose and velocity had been used to estimate the hand’s present trajectory which was in comparison with an estimated optimum trajectory to every object. The normalized similarity between the 2 trajectories outlined the probability of every object to be the goal of the present motion.

 Determine 1: Gaze options (prime) and movement options (backside) used for intention estimation. In each movies the article highlighted in inexperienced is the more than likely goal of visible consideration and of hand motion, respectively.
Determine 1: Gaze options (prime) and movement options (backside) used for intention estimation. In each movies the article highlighted in inexperienced is the more than likely goal of visible consideration and of hand motion, respectively.
These options together with the binary greedy state had been used to coach two Gaussian Hidden Markov Fashions, one on decide and one on place sequences. For 12 completely different intentions (choosing of 6 completely different objects and inserting at 6 completely different areas) the overall accuracy (F1 rating) was above 80%, even for occluded objects. Importantly, for each actions already 0.5 seconds earlier than the tip of the motion a prediction with over 90% accuracy was out there for a minimum of 70% of the observations. This is able to permit for an helping plan to be instantiated and executed by the robotic.
We additionally performed an ablation research to find out the contribution of various function mixtures. Whereas the fashions with gaze, movement, and greedy options carried out higher within the cross validation, the advance with respect to solely gaze and greedy state was minimal. Even when checking obstacles close by at first, actually, the gaze was already on the goal earlier than the hand trajectory grew to become sufficiently discriminative.
We additionally ascertained that our fashions may generalize from one hand to the opposite (when fed the corresponding hand movement options), therefore the identical fashions might be used to concurrently estimate every hand intention. By feeding every hand prediction to a easy rule-based framework, fundamental bimanual intentions may be acknowledged. So, for instance, reaching for an object with the left hand whereas the correct hand goes to position the identical object on the left hand is taken into account a bimanual handover.
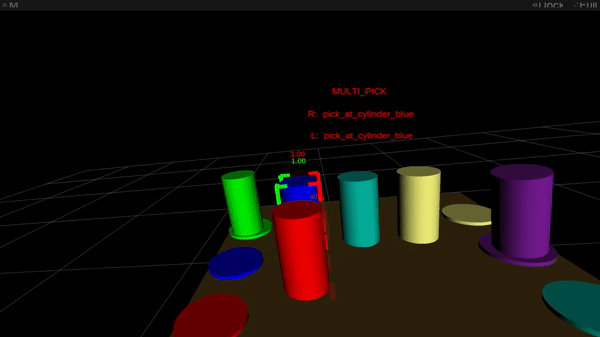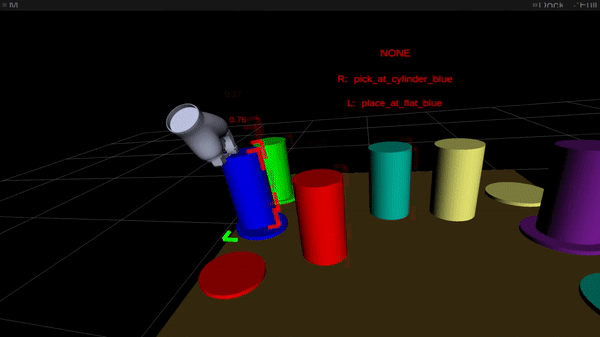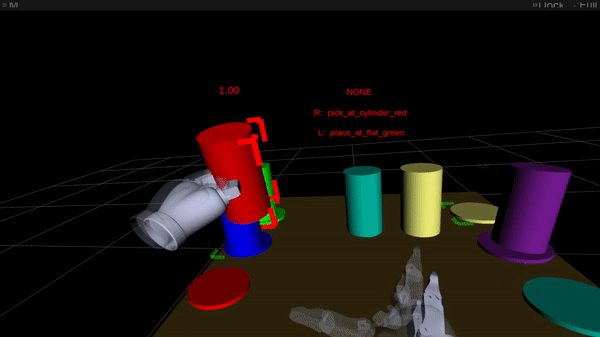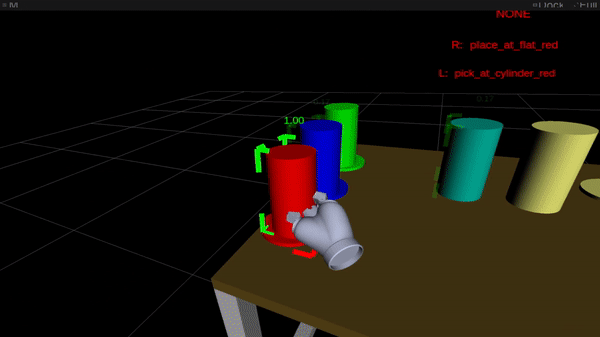 Determine 2: On-line intention estimation: the purple body denotes the present right-hand intention prediction, the inexperienced body the left-hand prediction. Above the scene, the bimanual intention is proven in capital letters.
Determine 2: On-line intention estimation: the purple body denotes the present right-hand intention prediction, the inexperienced body the left-hand prediction. Above the scene, the bimanual intention is proven in capital letters.
Such an intention estimation mannequin may assist an operator to execute such manipulations with out specializing in choosing the parameters for the precise motor execution of the decide and place, one thing we don’t normally do consciously in pure eye-hand coordination, since we automated such cognitive processes. For instance, as soon as a greedy intention is estimated with sufficient confidence, the robotic may autonomously choose the perfect grasp and greedy place and execute the grasp, relieving the operator of fastidiously monitoring a grasp with out tactile suggestions and probably with inaccurate depth estimation.
Additional, even when in our setup movement options weren’t decisive for early intention prediction, they may play a bigger function in additional complicated settings and when extending the spectrum of bimanual manipulations.
Mixed with appropriate shared management insurance policies and suggestions visualizations, such programs may additionally allow untrained operators to manage robotic manipulators transparently and successfully for longer occasions, bettering the overall psychological workload of distant operation.
References
Belardinelli, A., Kondapally, A. R., Ruiken, D., Tanneberg, D., & Watabe, T. (2022). Intention estimation from gaze and movement options for human-robot shared-control object manipulation. 2022 IEEE/RSJ Worldwide Convention on Clever Robots and Methods (IROS), 2022.
Hayhoe, M. M., McKinney, T., Chajka, Ok., & Pelz, J. B. (2012). Predictive eye actions in pure imaginative and prescient. Experimental mind analysis, 217(1), 125-136.
Rea, D. J., & Website positioning, S. H. (2022). Nonetheless Not Solved: A Name for Renewed Give attention to Consumer-Centered Teleoperation Interfaces. Frontiers in Robotics and AI, 9.

Anna Belardinelli
is Principal Scientist on the Honda Analysis Institute Europe.

AIhub
is a non-profit devoted to connecting the AI group to the general public by offering free, high-quality data in AI.
AIhub
is a non-profit devoted to connecting the AI group to the general public by offering free, high-quality data in AI.
{kind=link}