

In our earlier weblog put up we talked about tips on how to simplify the deployment and monitoring of basis fashions with DataRobot MLOps. We took a pre-trained mannequin from HuggingFace utilizing Tensorflow, and we wrote a easy inference script and uploaded the script and the saved mannequin as a customized mannequin bundle to DataRobot MLOps. We then simply deployed the pre-trained basis mannequin on DataRobot servers in only a few minutes.
On this weblog put up, we’ll showcase how one can effortlessly acquire a big enchancment within the inference pace of the identical mannequin whereas reducing its useful resource consumption. In our walkthrough, you’ll study that the one factor wanted is to transform your language mannequin to the ONNX format. The native assist for the ONNX Runtime in DataRobot will maintain the remaining.
Why Are Massive Language Fashions Difficult for Inference?
Beforehand, we talked about what language fashions are. The neural structure of huge language fashions can have billions of parameters. Having an enormous variety of parameters means these fashions will likely be hungry for assets and gradual to foretell. Due to this, they’re difficult to serve for inference with excessive efficiency. As well as, we wish these fashions to not solely course of one enter at a time, but additionally course of batches of inputs and eat them extra effectively. The excellent news is that we’ve a means of bettering their efficiency and throughput by accelerating their inference course of, due to the capabilities of the ONNX Runtime.
What Is ONNX and the ONNX Runtime?
ONNX (Open Neural Community Change) is an open customary format to signify machine studying (ML) fashions constructed on varied frameworks equivalent to PyTorch, Tensorflow/Keras, scikit-learn. ONNX Runtime can also be an open supply undertaking that’s constructed on the ONNX customary. It’s an inference engine optimized to speed up the inference strategy of fashions transformed to the ONNX format throughout a variety of working methods, languages, and {hardware} platforms.
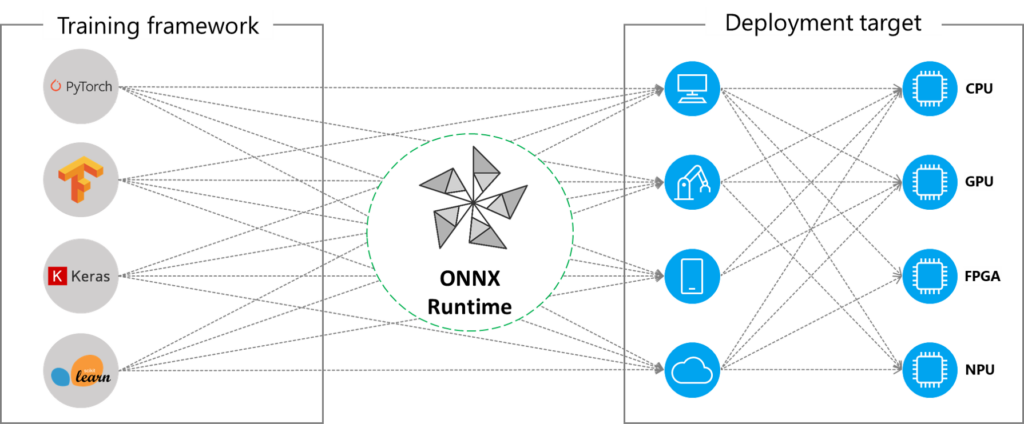
ONNX and its runtime collectively kind the premise of standardizing and accelerating mannequin inference in manufacturing environments. By means of sure optimization strategies1, ONNX Runtime accelerates mannequin inference on totally different platforms, equivalent to cell units, cloud, or edge environments. It gives an abstraction by leveraging these platforms’ compute capabilities by a single API interface.
As well as, by changing fashions to ONNX, we acquire the benefit of framework interoperability as we are able to export fashions skilled in varied ML frameworks to ONNX and vice versa, load beforehand exported ONNX fashions into reminiscence, and use them in our ML framework of alternative.
Accelerating Transformer-Based mostly Mannequin Inference with ONNX Runtime
Numerous benchmarks executed by impartial engineering groups within the trade have demonstrated that transformer-based fashions can considerably profit from ONNX Runtime optimizations to cut back latency and enhance throughput on CPUs.
Some examples embody Microsoft’s work round BERT mannequin optimization utilizing ONNX Runtime2, Twitter benchmarking outcomes for transformer CPU inference in Google Cloud3, and sentence transformers acceleration with Hugging Face Optimum4.
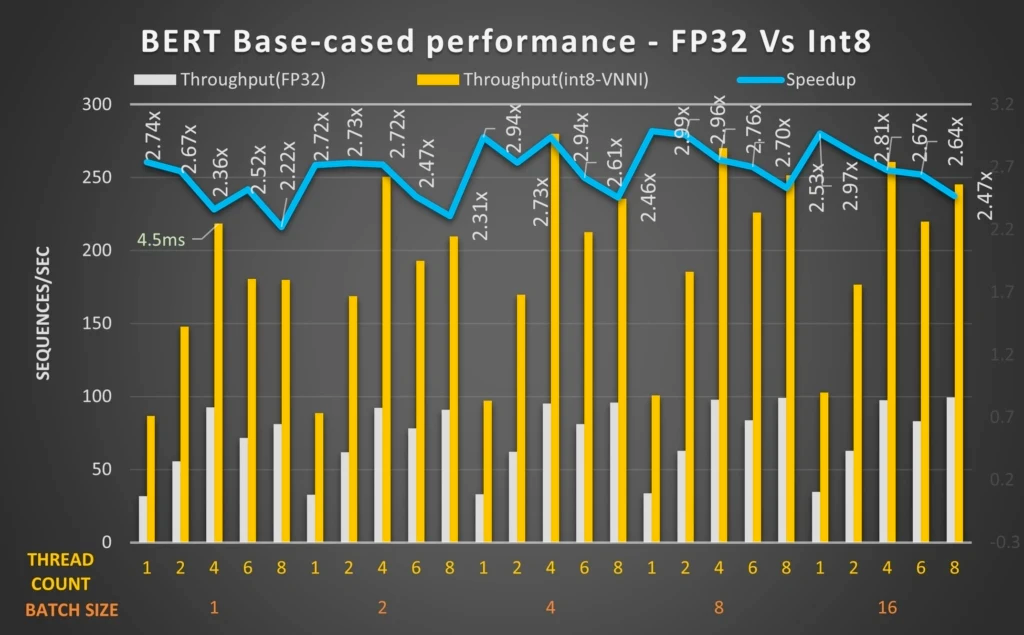
These benchmarks display that we are able to considerably enhance throughput and efficiency for transformer-based NLP fashions, particularly by quantization. For instance, in Microsoft staff’s benchmark above, the quantized BERT 12-layer mannequin with Intel® DL Enhance: VNNI and ONNX Runtime can obtain as much as 2.9 occasions efficiency features.
How Does DataRobot MLOps Natively Assist ONNX?
On your modeling or inference workflows, you’ll be able to combine your customized code into DataRobot with these two mechanisms:
- As a customized job: Whereas DataRobot gives lots of of built-in duties, there are conditions the place you want preprocessing or modeling strategies that aren’t at the moment supported out-of-the-box. To fill this hole, you’ll be able to convey a customized job that implements a lacking methodology, plug that job right into a blueprint inside DataRobot, after which prepare, consider, and deploy that blueprint in the identical means as you’d for any DataRobot-generated blueprint. You may overview how the method works right here.
- As a customized inference mannequin: This is perhaps a pre-trained mannequin or consumer code ready for inference, or a mix of each. An inference mannequin can have a predefined enter/output schema for classification/regression/anomaly detection or be fully unstructured. You may learn extra particulars on deploying your customized inference fashions right here.
In each circumstances, with a view to run your customized fashions on the DataRobot AI Platform with MLOps assist, you first choose certainly one of our public_dropin_environments equivalent to Python3 + PyTorch, Python3 + Keras/Tensorflow or Python3 + ONNX. These environments every outline the libraries obtainable within the atmosphere and supply a template. Your personal dependency necessities may be utilized to certainly one of these base environments to create a runtime atmosphere to your customized duties or customized inference fashions.
The bonus perk of DataRobot execution environments is that when you’ve got a single mannequin artifact and your mannequin conforms to sure enter/output constructions, that means you do not want a customized inference script to rework the enter request or the uncooked predictions, you don’t even want to supply a customized script in your uploaded mannequin bundle. Within the ONNX case, in case you solely need to predict with a single .onnx file, and this mannequin file conforms to the structured specification, when you choose Python3+ONNX base atmosphere to your customized mannequin bundle, DataRobot MLOps will know tips on how to load this mannequin into reminiscence and predict with it. To study extra and get your arms on easy-to-reproduce examples, please go to the customized inference mannequin templates part in our customized fashions repository.
Walkthrough
After studying all this details about the efficiency advantages and the relative simplicity of implementing fashions by ONNX, I’m positive you’re greater than excited to get began.
To display an end-to-end instance, we’ll carry out the next steps:
- Seize the identical basis mannequin in our earlier weblog put up and put it aside in your native drive.
- Export the saved Tensorflow mannequin to ONNX format.
- Bundle the ONNX mannequin artifact together with a customized inference (customized.py) script.
- Add the customized mannequin bundle to DataRobot MLOps on the ONNX base atmosphere.
- Create a deployment.
- Ship prediction requests to the deployment endpoint.
For brevity, we’ll solely present the extra and modified steps you’ll carry out on high of the walkthrough from our earlier weblog, however the end-to-end implementation is offered on this Google Colab pocket book underneath the DataRobot Neighborhood repository.
Changing the Basis Mannequin to ONNX
For this tutorial, we’ll use the transformer library’s ONNX conversion software to transform our query answering LLM into the ONNX format as beneath.
FOUNDATION_MODEL = "bert-large-uncased-whole-word-masking-finetuned-squad"
!python -m transformers.onnx --model=$FOUNDATION_MODEL --feature=question-answering $BASE_PATH
Modifying Your Customized Inference Script to Use Your ONNX Mannequin
For inferencing with this mannequin on DataRobot MLOps, we’ll have our customized.py script load the ONNX mannequin into reminiscence in an ONNX runtime session and deal with the incoming prediction requests as follows:
%%writefile $BASE_PATH/customized.py
"""
Copyright 2021 DataRobot, Inc. and its associates.
All rights reserved.
That is proprietary supply code of DataRobot, Inc. and its associates.
Launched underneath the phrases of DataRobot Device and Utility Settlement.
"""
import json
import os
import io
from transformers import AutoTokenizer
import onnxruntime as ort
import numpy as np
import pandas as pd
def load_model(input_dir):
world model_load_duration
onnx_path = os.path.be part of(input_dir, "mannequin.onnx")
tokenizer_path = os.path.be part of(input_dir)
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
sess = ort.InferenceSession(onnx_path)
return sess, tokenizer
def _get_answer_in_text(output, input_ids, idx, tokenizer):
answer_start = np.argmax(output[0], axis=1)[idx]
answer_end = (np.argmax(output[1], axis=1) + 1)[idx]
reply = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
return reply
def score_unstructured(mannequin, information, question, **kwargs):
world model_load_duration
sess, tokenizer = mannequin
# Assume batch enter is distributed with mimetype:"textual content/csv"
# Deal with as single prediction enter if no mimetype is about
is_batch = kwargs["mimetype"] == "textual content/csv"
if is_batch:
input_pd = pd.read_csv(io.StringIO(information), sep="|")
input_pairs = record(zip(input_pd["context"], input_pd["question"]))
inputs = tokenizer.batch_encode_plus(
input_pairs, add_special_tokens=True, padding=True, return_tensors="np"
)
input_ids = inputs["input_ids"]
output = sess.run(["start_logits", "end_logits"], input_feed=dict(inputs))
responses = []
for i, row in input_pd.iterrows():
reply = _get_answer_in_text(output, input_ids[i], i, tokenizer)
response = {
"context": row["context"],
"query": row["question"],
"reply": reply,
}
responses.append(response)
to_return = json.dumps(
{
"predictions": responses
}
)
else:
data_dict = json.masses(information)
context, query = data_dict["context"], data_dict["question"]
inputs = tokenizer(
query,
context,
add_special_tokens=True,
padding=True,
return_tensors="np",
)
input_ids = inputs["input_ids"][0]
output = sess.run(["start_logits", "end_logits"], input_feed=dict(inputs))
reply = _get_answer_in_text(output, input_ids, 0, tokenizer)
to_return = json.dumps(
{
"context": context,
"query": query,
"reply": reply
}
)
return to_returnCreating your customized inference mannequin deployment on DataRobot’s ONNX base atmosphere
As the ultimate change, we’ll create this tradition mannequin’s deployment on the ONNX base atmosphere of DataRobot MLOps as beneath:
deployment = deploy_to_datarobot(BASE_PATH,
"ONNX",
"bert-onnx-questionAnswering",
"Pretrained BERT mannequin, fine-tuned on SQUAD for query answering")When the deployment is prepared, we’ll check our customized mannequin with our check enter and guarantee that we’re getting our questions answered by our pre-trained LLM:
datarobot_predict(test_input, deployment.id)
Efficiency Comparability
Now that we’ve the whole lot prepared, it’s time to match our earlier Tensorflow deployment with the ONNX different.
For our benchmarking functions, we constrained our customized mannequin deployment to solely have 4GB of reminiscence from our MLOps settings in order that we may evaluate the Tensorflow and ONNX options underneath useful resource constraints.
As may be seen from the outcomes beneath, our mannequin in ONNX predicts 1.5x quicker than its Tensorflow counterpart. And this end result may be seen by simply an extra primary ONNX export, (i.e. with none additional optimization configurations, equivalent to quantization).
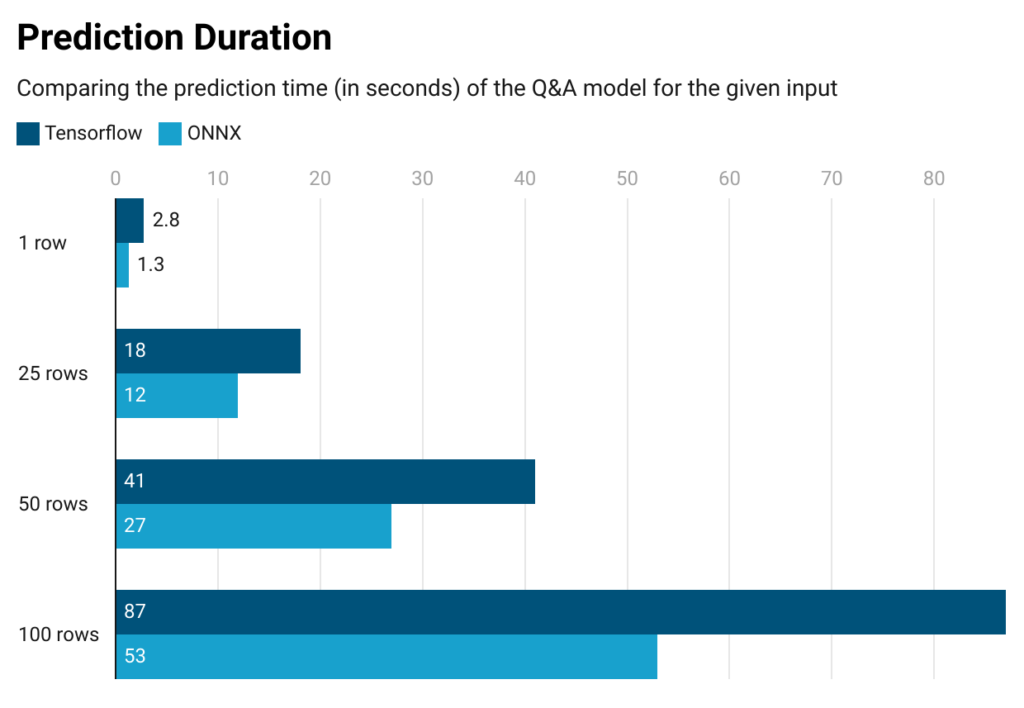
Concerning useful resource consumption, someplace after ~100 rows, our Tensorflow mannequin deployment begins returning Out of Reminiscence (OOM) errors, that means that this mannequin would require greater than 4GBs of reminiscence to course of and predict for ~100 rows of enter. Then again, our ONNX mannequin deployment can calculate predictions as much as ~450 rows with out throwing an OOM error. As a conclusion for our use case, the truth that the Tensorflow mannequin handles as much as 100 rows, whereas its ONNX equal handles as much as 450 rows exhibits that the ONNX mannequin is extra useful resource environment friendly, as a result of it makes use of a lot much less reminiscence.
Begin Leveraging ONNX for Your Customized Fashions
By leveraging the open supply ONNX customary and the ONNX Runtime, AI builders can make the most of the framework interoperability and accelerated inference efficiency, particularly for transformer-based giant language fashions on their most well-liked execution atmosphere. With its native ONNX assist, DataRobot MLOps makes it simple for organizations to realize worth from their machine studying deployments with optimized inference pace and throughput.
On this weblog put up, we confirmed how easy it’s to make use of a big language mannequin for query answering in ONNX as a DataRobot customized mannequin and the way a lot inference efficiency and useful resource effectivity you’ll be able to acquire with a easy conversion step. To copy this workflow, you will discover the end-to-end pocket book underneath the DataRobot Neighborhood repo, together with many different tutorials to empower AI builders with the capabilities of DataRobot.
1 ONNX Runtime, Mannequin Optimizations
2 Microsoft, Optimizing BERT mannequin for Intel CPU Cores utilizing ONNX runtime default execution supplier
3 Twitter Weblog, Rushing up Transformer CPU inference in Google Cloud
4 Philipp Schmid, Speed up Sentence Transformers with Hugging Face Optimum
5 Microsoft, Optimizing BERT mannequin for Intel CPU Cores utilizing ONNX runtime default execution supplier
Concerning the writer

Aslı Sabancı Demiröz is a Senior Machine Studying Engineer at DataRobot. She holds a BS in Laptop Engineering with a double main in Management Engineering from Istanbul Technical College. Working within the workplace of the CTO, she enjoys being on the coronary heart of DataRobot’s R&D to drive innovation. Her ardour lies within the deep studying area and he or she particularly enjoys creating highly effective integrations between platform and utility layers within the ML ecosystem, aiming to make the entire larger than the sum of the components.
{kind=link}