
Coaching a convnet with a small dataset
Having to coach an image-classification mannequin utilizing little or no information is a standard state of affairs, which you’ll possible encounter in apply should you ever do laptop imaginative and prescient in an expert context. A “few” samples can imply anyplace from a couple of hundred to a couple tens of 1000’s of photographs. As a sensible instance, we’ll give attention to classifying photographs as canine or cats, in a dataset containing 4,000 footage of cats and canine (2,000 cats, 2,000 canine). We’ll use 2,000 footage for coaching – 1,000 for validation, and 1,000 for testing.
In Chapter 5 of the Deep Studying with R ebook we evaluate three methods for tackling this drawback. The primary of those is coaching a small mannequin from scratch on what little information you will have (which achieves an accuracy of 82%). Subsequently we use function extraction with a pretrained community (leading to an accuracy of 90%) and fine-tuning a pretrained community (with a remaining accuracy of 97%). On this submit we’ll cowl solely the second and third methods.
The relevance of deep studying for small-data issues
You’ll typically hear that deep studying solely works when a number of information is out there. That is legitimate partly: one elementary attribute of deep studying is that it may possibly discover attention-grabbing options within the coaching information by itself, with none want for handbook function engineering, and this may solely be achieved when a number of coaching examples can be found. That is very true for issues the place the enter samples are very high-dimensional, like photographs.
However what constitutes a number of samples is relative – relative to the dimensions and depth of the community you’re making an attempt to coach, for starters. It isn’t potential to coach a convnet to unravel a posh drawback with only a few tens of samples, however a couple of hundred can doubtlessly suffice if the mannequin is small and properly regularized and the duty is easy. As a result of convnets study native, translation-invariant options, they’re extremely information environment friendly on perceptual issues. Coaching a convnet from scratch on a really small picture dataset will nonetheless yield cheap outcomes regardless of a relative lack of information, with out the necessity for any customized function engineering. You’ll see this in motion on this part.
What’s extra, deep-learning fashions are by nature extremely repurposable: you may take, say, an image-classification or speech-to-text mannequin skilled on a large-scale dataset and reuse it on a considerably totally different drawback with solely minor adjustments. Particularly, within the case of laptop imaginative and prescient, many pretrained fashions (normally skilled on the ImageNet dataset) are actually publicly accessible for obtain and can be utilized to bootstrap highly effective imaginative and prescient fashions out of little or no information. That’s what you’ll do within the subsequent part. Let’s begin by getting your fingers on the information.
Downloading the information
The Canines vs. Cats dataset that you just’ll use isn’t packaged with Keras. It was made accessible by Kaggle as a part of a computer-vision competitors in late 2013, again when convnets weren’t mainstream. You may obtain the unique dataset from https://www.kaggle.com/c/dogs-vs-cats/information (you’ll have to create a Kaggle account should you don’t have already got one – don’t fear, the method is painless).
The photographs are medium-resolution coloration JPEGs. Listed here are some examples:

Unsurprisingly, the dogs-versus-cats Kaggle competitors in 2013 was gained by entrants who used convnets. One of the best entries achieved as much as 95% accuracy. Beneath you’ll find yourself with a 97% accuracy, despite the fact that you’ll practice your fashions on lower than 10% of the information that was accessible to the rivals.
This dataset accommodates 25,000 photographs of canine and cats (12,500 from every class) and is 543 MB (compressed). After downloading and uncompressing it, you’ll create a brand new dataset containing three subsets: a coaching set with 1,000 samples of every class, a validation set with 500 samples of every class, and a check set with 500 samples of every class.
Following is the code to do that:
original_dataset_dir <- "~/Downloads/kaggle_original_data"
base_dir <- "~/Downloads/cats_and_dogs_small"
dir.create(base_dir)
train_dir <- file.path(base_dir, "practice")
dir.create(train_dir)
validation_dir <- file.path(base_dir, "validation")
dir.create(validation_dir)
test_dir <- file.path(base_dir, "check")
dir.create(test_dir)
train_cats_dir <- file.path(train_dir, "cats")
dir.create(train_cats_dir)
train_dogs_dir <- file.path(train_dir, "canine")
dir.create(train_dogs_dir)
validation_cats_dir <- file.path(validation_dir, "cats")
dir.create(validation_cats_dir)
validation_dogs_dir <- file.path(validation_dir, "canine")
dir.create(validation_dogs_dir)
test_cats_dir <- file.path(test_dir, "cats")
dir.create(test_cats_dir)
test_dogs_dir <- file.path(test_dir, "canine")
dir.create(test_dogs_dir)
fnames <- paste0("cat.", 1:1000, ".jpg")
file.copy(file.path(original_dataset_dir, fnames),
file.path(train_cats_dir))
fnames <- paste0("cat.", 1001:1500, ".jpg")
file.copy(file.path(original_dataset_dir, fnames),
file.path(validation_cats_dir))
fnames <- paste0("cat.", 1501:2000, ".jpg")
file.copy(file.path(original_dataset_dir, fnames),
file.path(test_cats_dir))
fnames <- paste0("canine.", 1:1000, ".jpg")
file.copy(file.path(original_dataset_dir, fnames),
file.path(train_dogs_dir))
fnames <- paste0("canine.", 1001:1500, ".jpg")
file.copy(file.path(original_dataset_dir, fnames),
file.path(validation_dogs_dir))
fnames <- paste0("canine.", 1501:2000, ".jpg")
file.copy(file.path(original_dataset_dir, fnames),
file.path(test_dogs_dir))Utilizing a pretrained convnet
A standard and extremely efficient strategy to deep studying on small picture datasets is to make use of a pretrained community. A pretrained community is a saved community that was beforehand skilled on a big dataset, usually on a large-scale image-classification process. If this authentic dataset is massive sufficient and basic sufficient, then the spatial hierarchy of options discovered by the pretrained community can successfully act as a generic mannequin of the visible world, and therefore its options can show helpful for a lot of totally different computer-vision issues, despite the fact that these new issues could contain fully totally different lessons than these of the unique process. For example, you may practice a community on ImageNet (the place lessons are largely animals and on a regular basis objects) after which repurpose this skilled community for one thing as distant as figuring out furnishings objects in photographs. Such portability of discovered options throughout totally different issues is a key benefit of deep studying in comparison with many older, shallow-learning approaches, and it makes deep studying very efficient for small-data issues.
On this case, let’s think about a big convnet skilled on the ImageNet dataset (1.4 million labeled photographs and 1,000 totally different lessons). ImageNet accommodates many animal lessons, together with totally different species of cats and canine, and you’ll thus anticipate to carry out properly on the dogs-versus-cats classification drawback.
You’ll use the VGG16 structure, developed by Karen Simonyan and Andrew Zisserman in 2014; it’s a easy and extensively used convnet structure for ImageNet. Though it’s an older mannequin, removed from the present cutting-edge and considerably heavier than many different latest fashions, I selected it as a result of its structure is much like what you’re already conversant in and is straightforward to know with out introducing any new ideas. This can be your first encounter with one among these cutesy mannequin names – VGG, ResNet, Inception, Inception-ResNet, Xception, and so forth; you’ll get used to them, as a result of they’ll come up ceaselessly should you hold doing deep studying for laptop imaginative and prescient.
There are two methods to make use of a pretrained community: function extraction and fine-tuning. We’ll cowl each of them. Let’s begin with function extraction.
Characteristic extraction consists of utilizing the representations discovered by a earlier community to extract attention-grabbing options from new samples. These options are then run via a brand new classifier, which is skilled from scratch.
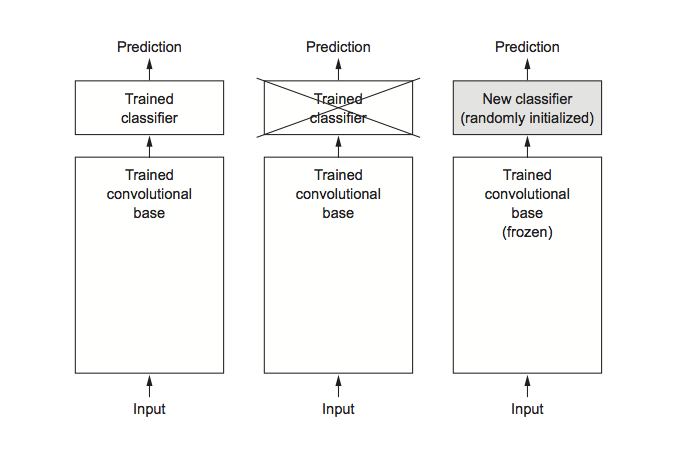
As you noticed beforehand, convnets used for picture classification comprise two components: they begin with a sequence of pooling and convolution layers, they usually finish with a densely linked classifier. The primary half is known as the convolutional base of the mannequin. Within the case of convnets, function extraction consists of taking the convolutional base of a beforehand skilled community, working the brand new information via it, and coaching a brand new classifier on prime of the output.

Why solely reuse the convolutional base? May you reuse the densely linked classifier as properly? Usually, doing so ought to be averted. The reason being that the representations discovered by the convolutional base are more likely to be extra generic and subsequently extra reusable: the function maps of a convnet are presence maps of generic ideas over an image, which is more likely to be helpful whatever the computer-vision drawback at hand. However the representations discovered by the classifier will essentially be particular to the set of lessons on which the mannequin was skilled – they’ll solely comprise details about the presence likelihood of this or that class in the whole image. Moreover, representations present in densely linked layers not comprise any details about the place objects are positioned within the enter picture: these layers do away with the notion of house, whereas the article location remains to be described by convolutional function maps. For issues the place object location issues, densely linked options are largely ineffective.
Word that the extent of generality (and subsequently reusability) of the representations extracted by particular convolution layers relies on the depth of the layer within the mannequin. Layers that come earlier within the mannequin extract native, extremely generic function maps (resembling visible edges, colours, and textures), whereas layers which are larger up extract more-abstract ideas (resembling “cat ear” or “canine eye”). So in case your new dataset differs rather a lot from the dataset on which the unique mannequin was skilled, chances are you’ll be higher off utilizing solely the primary few layers of the mannequin to do function extraction, fairly than utilizing the whole convolutional base.
On this case, as a result of the ImageNet class set accommodates a number of canine and cat lessons, it’s more likely to be useful to reuse the data contained within the densely linked layers of the unique mannequin. However we’ll select to not, so as to cowl the extra basic case the place the category set of the brand new drawback doesn’t overlap the category set of the unique mannequin.
Let’s put this in apply by utilizing the convolutional base of the VGG16 community, skilled on ImageNet, to extract attention-grabbing options from cat and canine photographs, after which practice a dogs-versus-cats classifier on prime of those options.
The VGG16 mannequin, amongst others, comes prepackaged with Keras. Right here’s the listing of image-classification fashions (all pretrained on the ImageNet dataset) which are accessible as a part of Keras:
- Xception
- Inception V3
- ResNet50
- VGG16
- VGG19
- MobileNet
Let’s instantiate the VGG16 mannequin.
You move three arguments to the operate:
weightsspecifies the burden checkpoint from which to initialize the mannequin.include_toprefers to together with (or not) the densely linked classifier on prime of the community. By default, this densely linked classifier corresponds to the 1,000 lessons from ImageNet. Since you intend to make use of your personal densely linked classifier (with solely two lessons:catandcanine), you don’t want to incorporate it.input_shapeis the form of the picture tensors that you just’ll feed to the community. This argument is only optionally available: should you don’t move it, the community will be capable to course of inputs of any measurement.
Right here’s the element of the structure of the VGG16 convolutional base. It’s much like the straightforward convnets you’re already conversant in:
Layer (kind) Output Form Param #
================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
________________________________________________________________
block1_conv1 (Convolution2D) (None, 150, 150, 64) 1792
________________________________________________________________
block1_conv2 (Convolution2D) (None, 150, 150, 64) 36928
________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
________________________________________________________________
block2_conv1 (Convolution2D) (None, 75, 75, 128) 73856
________________________________________________________________
block2_conv2 (Convolution2D) (None, 75, 75, 128) 147584
________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
________________________________________________________________
block3_conv1 (Convolution2D) (None, 37, 37, 256) 295168
________________________________________________________________
block3_conv2 (Convolution2D) (None, 37, 37, 256) 590080
________________________________________________________________
block3_conv3 (Convolution2D) (None, 37, 37, 256) 590080
________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
________________________________________________________________
block4_conv1 (Convolution2D) (None, 18, 18, 512) 1180160
________________________________________________________________
block4_conv2 (Convolution2D) (None, 18, 18, 512) 2359808
________________________________________________________________
block4_conv3 (Convolution2D) (None, 18, 18, 512) 2359808
________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
________________________________________________________________
block5_conv1 (Convolution2D) (None, 9, 9, 512) 2359808
________________________________________________________________
block5_conv2 (Convolution2D) (None, 9, 9, 512) 2359808
________________________________________________________________
block5_conv3 (Convolution2D) (None, 9, 9, 512) 2359808
________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
================================================================
Complete params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0The ultimate function map has form (4, 4, 512). That’s the function on prime of which you’ll stick a densely linked classifier.
At this level, there are two methods you could possibly proceed:
-
Operating the convolutional base over your dataset, recording its output to an array on disk, after which utilizing this information as enter to a standalone, densely linked classifier much like these you noticed partly 1 of this ebook. This resolution is quick and low cost to run, as a result of it solely requires working the convolutional base as soon as for each enter picture, and the convolutional base is by far the costliest a part of the pipeline. However for a similar purpose, this method gained’t let you use information augmentation.
-
Extending the mannequin you will have (
conv_base) by including dense layers on prime, and working the entire thing finish to finish on the enter information. This can let you use information augmentation, as a result of each enter picture goes via the convolutional base each time it’s seen by the mannequin. However for a similar purpose, this method is way costlier than the primary.
On this submit we’ll cowl the second method intimately (within the ebook we cowl each). Word that this method is so costly that it’s best to solely try it if in case you have entry to a GPU – it’s completely intractable on a CPU.
As a result of fashions behave similar to layers, you may add a mannequin (like conv_base) to a sequential mannequin similar to you’ll add a layer.
mannequin <- keras_model_sequential() %>%
conv_base %>%
layer_flatten() %>%
layer_dense(models = 256, activation = "relu") %>%
layer_dense(models = 1, activation = "sigmoid")That is what the mannequin appears like now:
Layer (kind) Output Form Param #
================================================================
vgg16 (Mannequin) (None, 4, 4, 512) 14714688
________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
________________________________________________________________
dense_1 (Dense) (None, 256) 2097408
________________________________________________________________
dense_2 (Dense) (None, 1) 257
================================================================
Complete params: 16,812,353
Trainable params: 16,812,353
Non-trainable params: 0As you may see, the convolutional base of VGG16 has 14,714,688 parameters, which may be very massive. The classifier you’re including on prime has 2 million parameters.
Earlier than you compile and practice the mannequin, it’s essential to freeze the convolutional base. Freezing a layer or set of layers means stopping their weights from being up to date throughout coaching. In the event you don’t do that, then the representations that have been beforehand discovered by the convolutional base shall be modified throughout coaching. As a result of the dense layers on prime are randomly initialized, very massive weight updates can be propagated via the community, successfully destroying the representations beforehand discovered.
In Keras, you freeze a community utilizing the freeze_weights() operate:
size(mannequin$trainable_weights)[1] 30freeze_weights(conv_base)
size(mannequin$trainable_weights)[1] 4With this setup, solely the weights from the 2 dense layers that you just added shall be skilled. That’s a complete of 4 weight tensors: two per layer (the principle weight matrix and the bias vector). Word that to ensure that these adjustments to take impact, you should first compile the mannequin. In the event you ever modify weight trainability after compilation, it’s best to then recompile the mannequin, or these adjustments shall be ignored.
Utilizing information augmentation
Overfitting is attributable to having too few samples to study from, rendering you unable to coach a mannequin that may generalize to new information. Given infinite information, your mannequin can be uncovered to each potential facet of the information distribution at hand: you’ll by no means overfit. Information augmentation takes the strategy of producing extra coaching information from present coaching samples, by augmenting the samples by way of a variety of random transformations that yield believable-looking photographs. The aim is that at coaching time, your mannequin won’t ever see the very same image twice. This helps expose the mannequin to extra points of the information and generalize higher.
In Keras, this may be accomplished by configuring a variety of random transformations to be carried out on the pictures learn by an image_data_generator(). For instance:
train_datagen = image_data_generator(
rescale = 1/255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = TRUE,
fill_mode = "nearest"
)These are only a few of the choices accessible (for extra, see the Keras documentation). Let’s shortly go over this code:
rotation_rangeis a price in levels (0–180), a spread inside which to randomly rotate footage.width_shiftandheight_shiftare ranges (as a fraction of complete width or peak) inside which to randomly translate footage vertically or horizontally.shear_rangeis for randomly making use of shearing transformations.zoom_rangeis for randomly zooming inside footage.horizontal_flipis for randomly flipping half the pictures horizontally – related when there aren’t any assumptions of horizontal asymmetry (for instance, real-world footage).fill_modeis the technique used for filling in newly created pixels, which might seem after a rotation or a width/peak shift.
Now we are able to practice our mannequin utilizing the picture information generator:
# Word that the validation information should not be augmented!
test_datagen <- image_data_generator(rescale = 1/255)
train_generator <- flow_images_from_directory(
train_dir, # Goal listing
train_datagen, # Information generator
target_size = c(150, 150), # Resizes all photographs to 150 × 150
batch_size = 20,
class_mode = "binary" # binary_crossentropy loss for binary labels
)
validation_generator <- flow_images_from_directory(
validation_dir,
test_datagen,
target_size = c(150, 150),
batch_size = 20,
class_mode = "binary"
)
mannequin %>% compile(
loss = "binary_crossentropy",
optimizer = optimizer_rmsprop(lr = 2e-5),
metrics = c("accuracy")
)
historical past <- mannequin %>% fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 30,
validation_data = validation_generator,
validation_steps = 50
)Let’s plot the outcomes. As you may see, you attain a validation accuracy of about 90%.

High-quality-tuning
One other extensively used method for mannequin reuse, complementary to function extraction, is fine-tuning
High-quality-tuning consists of unfreezing a couple of of the highest layers of a frozen mannequin base used for function extraction, and collectively coaching each the newly added a part of the mannequin (on this case, the absolutely linked classifier) and these prime layers. That is known as fine-tuning as a result of it barely adjusts the extra summary
representations of the mannequin being reused, so as to make them extra related for the issue at hand.

I said earlier that it’s essential to freeze the convolution base of VGG16 so as to have the ability to practice a randomly initialized classifier on prime. For a similar purpose, it’s solely potential to fine-tune the highest layers of the convolutional base as soon as the classifier on prime has already been skilled. If the classifier isn’t already skilled, then the error sign propagating via the community throughout coaching shall be too massive, and the representations beforehand discovered by the layers being fine-tuned shall be destroyed. Thus the steps for fine-tuning a community are as follows:
- Add your customized community on prime of an already-trained base community.
- Freeze the bottom community.
- Practice the half you added.
- Unfreeze some layers within the base community.
- Collectively practice each these layers and the half you added.
You already accomplished the primary three steps when doing function extraction. Let’s proceed with step 4: you’ll unfreeze your conv_base after which freeze particular person layers inside it.
As a reminder, that is what your convolutional base appears like:
Layer (kind) Output Form Param #
================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
________________________________________________________________
block1_conv1 (Convolution2D) (None, 150, 150, 64) 1792
________________________________________________________________
block1_conv2 (Convolution2D) (None, 150, 150, 64) 36928
________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
________________________________________________________________
block2_conv1 (Convolution2D) (None, 75, 75, 128) 73856
________________________________________________________________
block2_conv2 (Convolution2D) (None, 75, 75, 128) 147584
________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
________________________________________________________________
block3_conv1 (Convolution2D) (None, 37, 37, 256) 295168
________________________________________________________________
block3_conv2 (Convolution2D) (None, 37, 37, 256) 590080
________________________________________________________________
block3_conv3 (Convolution2D) (None, 37, 37, 256) 590080
________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
________________________________________________________________
block4_conv1 (Convolution2D) (None, 18, 18, 512) 1180160
________________________________________________________________
block4_conv2 (Convolution2D) (None, 18, 18, 512) 2359808
________________________________________________________________
block4_conv3 (Convolution2D) (None, 18, 18, 512) 2359808
________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
________________________________________________________________
block5_conv1 (Convolution2D) (None, 9, 9, 512) 2359808
________________________________________________________________
block5_conv2 (Convolution2D) (None, 9, 9, 512) 2359808
________________________________________________________________
block5_conv3 (Convolution2D) (None, 9, 9, 512) 2359808
________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
================================================================
Complete params: 14714688You’ll fine-tune all the layers from block3_conv1 and on. Why not fine-tune the whole convolutional base? You possibly can. However you should think about the next:
- Earlier layers within the convolutional base encode more-generic, reusable options, whereas layers larger up encode more-specialized options. It’s extra helpful to fine-tune the extra specialised options, as a result of these are those that should be repurposed in your new drawback. There can be fast-decreasing returns in fine-tuning decrease layers.
- The extra parameters you’re coaching, the extra you’re liable to overfitting. The convolutional base has 15 million parameters, so it could be dangerous to aim to coach it in your small dataset.
Thus, on this state of affairs, it’s technique to fine-tune solely a number of the layers within the convolutional base. Let’s set this up, ranging from the place you left off within the earlier instance.
unfreeze_weights(conv_base, from = "block3_conv1")Now you may start fine-tuning the community. You’ll do that with the RMSProp optimizer, utilizing a really low studying charge. The explanation for utilizing a low studying charge is that you just wish to restrict the magnitude of the modifications you make to the representations of the three layers you’re fine-tuning. Updates which are too massive could hurt these representations.
mannequin %>% compile(
loss = "binary_crossentropy",
optimizer = optimizer_rmsprop(lr = 1e-5),
metrics = c("accuracy")
)
historical past <- mannequin %>% fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 100,
validation_data = validation_generator,
validation_steps = 50
)Let’s plot our outcomes:

You’re seeing a pleasant 6% absolute enchancment in accuracy, from about 90% to above 96%.
Word that the loss curve doesn’t present any actual enchancment (in reality, it’s deteriorating). You might surprise, how might accuracy keep steady or enhance if the loss isn’t reducing? The reply is easy: what you show is a mean of pointwise loss values; however what issues for accuracy is the distribution of the loss values, not their common, as a result of accuracy is the results of a binary thresholding of the category likelihood predicted by the mannequin. The mannequin should still be enhancing even when this isn’t mirrored within the common loss.
Now you can lastly consider this mannequin on the check information:
test_generator <- flow_images_from_directory(
test_dir,
test_datagen,
target_size = c(150, 150),
batch_size = 20,
class_mode = "binary"
)mannequin %>% evaluate_generator(test_generator, steps = 50)$loss
[1] 0.2158171
$acc
[1] 0.965Right here you get a check accuracy of 96.5%. Within the authentic Kaggle competitors round this dataset, this might have been one of many prime outcomes. However utilizing trendy deep-learning methods, you managed to succeed in this outcome utilizing solely a small fraction of the coaching information accessible (about 10%). There’s a large distinction between having the ability to practice on 20,000 samples in comparison with 2,000 samples!
Take-aways: utilizing convnets with small datasets
Right here’s what it’s best to take away from the workouts previously two sections:
- Convnets are the most effective kind of machine-learning fashions for computer-vision duties. It’s potential to coach one from scratch even on a really small dataset, with first rate outcomes.
- On a small dataset, overfitting would be the important challenge. Information augmentation is a robust technique to struggle overfitting whenever you’re working with picture information.
- It’s straightforward to reuse an present convnet on a brand new dataset by way of function extraction. It is a beneficial method for working with small picture datasets.
- As a complement to function extraction, you need to use fine-tuning, which adapts to a brand new drawback a number of the representations beforehand discovered by an present mannequin. This pushes efficiency a bit additional.
Now you will have a stable set of instruments for coping with image-classification issues – particularly with small datasets.
{kind=link}