
Deep studying has not too long ago pushed great progress in a big selection of purposes, starting from lifelike picture era and spectacular retrieval techniques to language fashions that may maintain human-like conversations. Whereas this progress could be very thrilling, the widespread use of deep neural community fashions requires warning: as guided by Google’s AI Rules, we search to develop AI applied sciences responsibly by understanding and mitigating potential dangers, such because the propagation and amplification of unfair biases and defending person privateness.
Absolutely erasing the affect of the info requested to be deleted is difficult since, except for merely deleting it from databases the place it’s saved, it additionally requires erasing the affect of that information on different artifacts reminiscent of educated machine studying fashions. Furthermore, latest analysis [1, 2] has proven that in some circumstances it might be doable to deduce with excessive accuracy whether or not an instance was used to coach a machine studying mannequin utilizing membership inference assaults (MIAs). This could elevate privateness issues, because it implies that even when a person’s information is deleted from a database, it might nonetheless be doable to deduce whether or not that particular person’s information was used to coach a mannequin.
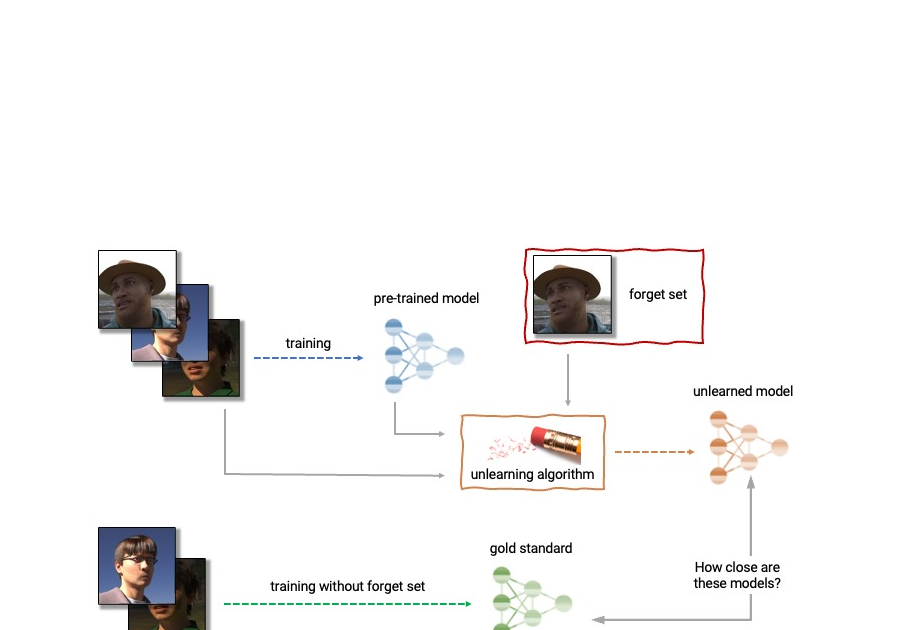
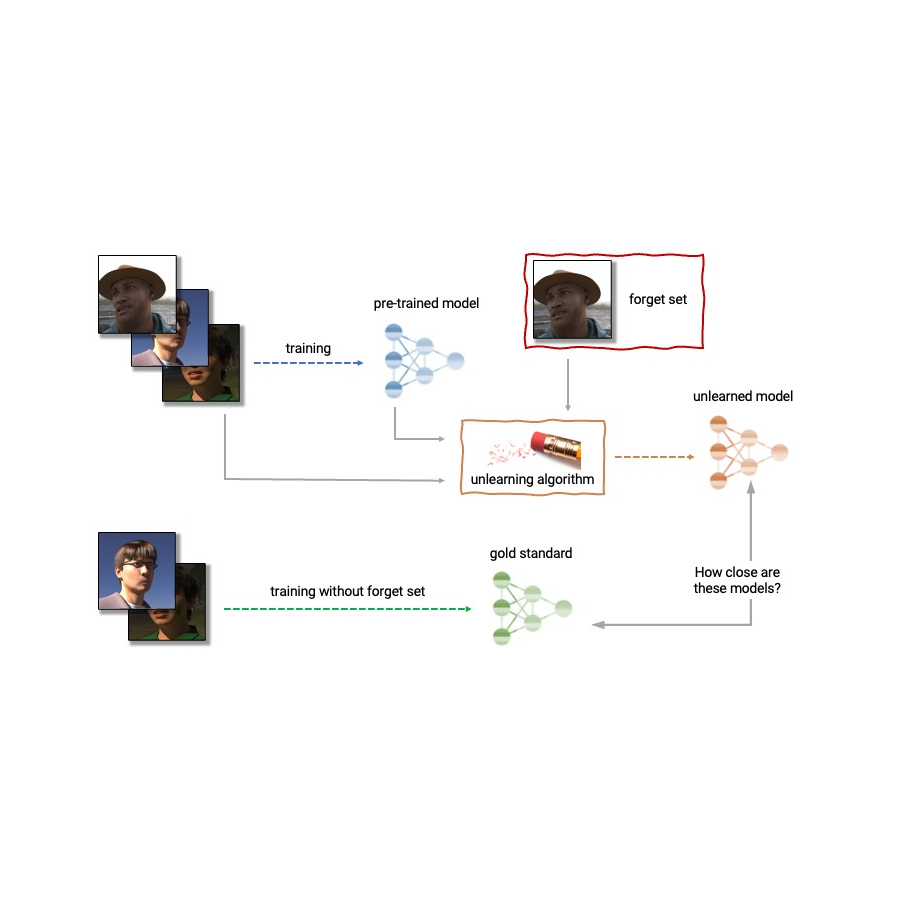
Given the above, machine unlearning is an emergent subfield of machine studying that goals to take away the affect of a selected subset of coaching examples — the “overlook set” — from a educated mannequin. Moreover, a great unlearning algorithm would take away the affect of sure examples whereas sustaining different helpful properties, such because the accuracy on the remainder of the prepare set and generalization to held-out examples. A simple solution to produce this unlearned mannequin is to retrain the mannequin on an adjusted coaching set that excludes the samples from the overlook set. Nonetheless, this isn’t at all times a viable possibility, as retraining deep fashions may be computationally costly. A really perfect unlearning algorithm would as an alternative use the already-trained mannequin as a place to begin and effectively make changes to take away the affect of the requested information.
Right this moment we’re thrilled to announce that we have teamed up with a broad group of educational and industrial researchers to prepare the first Machine Unlearning Problem. The competitors considers a sensible state of affairs during which after coaching, a sure subset of the coaching photographs should be forgotten to guard the privateness or rights of the people involved. The competitors might be hosted on Kaggle, and submissions might be mechanically scored by way of each forgetting high quality and mannequin utility. We hope that this competitors will assist advance the state-of-the-art in machine unlearning and encourage the event of environment friendly, efficient and moral unlearning algorithms.
Machine unlearning purposes
Machine unlearning has purposes past defending person privateness. As an example, one can use unlearning to erase inaccurate or outdated info from educated fashions (e.g., as a result of errors in labeling or modifications within the surroundings) or take away dangerous, manipulated, or outlier information.
The sector of machine unlearning is expounded to different areas of machine studying reminiscent of differential privateness, life-long studying, and equity. Differential privateness goals to ensure that no explicit coaching instance has too giant an affect on the educated mannequin; a stronger objective in comparison with that of unlearning, which solely requires erasing the affect of the designated overlook set. Life-long studying analysis goals to design fashions that may study constantly whereas sustaining previously-acquired abilities. As work on unlearning progresses, it might additionally open extra methods to spice up equity in fashions, by correcting unfair biases or disparate therapy of members belonging to totally different teams (e.g., demographics, age teams, and so on.).
 |
| Anatomy of unlearning. An unlearning algorithm takes as enter a pre-trained mannequin and a number of samples from the prepare set to unlearn (the “overlook set”). From the mannequin, overlook set, and retain set, the unlearning algorithm produces an up to date mannequin. A really perfect unlearning algorithm produces a mannequin that’s indistinguishable from the mannequin educated with out the overlook set. |
Challenges of machine unlearning
The issue of unlearning is advanced and multifaceted because it entails a number of conflicting aims: forgetting the requested information, sustaining the mannequin’s utility (e.g., accuracy on retained and held-out information), and effectivity. Due to this, present unlearning algorithms make totally different trade-offs. For instance, full retraining achieves profitable forgetting with out damaging mannequin utility, however with poor effectivity, whereas including noise to the weights achieves forgetting on the expense of utility.
Moreover, the analysis of forgetting algorithms within the literature has up to now been extremely inconsistent. Whereas some works report the classification accuracy on the samples to unlearn, others report distance to the absolutely retrained mannequin, and but others use the error price of membership inference assaults as a metric for forgetting high quality [4, 5, 6].
We consider that the inconsistency of analysis metrics and the shortage of a standardized protocol is a critical obstacle to progress within the discipline — we’re unable to make direct comparisons between totally different unlearning strategies within the literature. This leaves us with a myopic view of the relative deserves and downsides of various approaches, in addition to open challenges and alternatives for growing improved algorithms. To handle the problem of inconsistent analysis and to advance the state-of-the-art within the discipline of machine unlearning, we have teamed up with a broad group of educational and industrial researchers to prepare the primary unlearning problem.
Saying the primary Machine Unlearning Problem
We’re happy to announce the first Machine Unlearning Problem, which might be held as a part of the NeurIPS 2023 Competitors Monitor. The objective of the competitors is twofold. First, by unifying and standardizing the analysis metrics for unlearning, we hope to determine the strengths and weaknesses of various algorithms by means of apples-to-apples comparisons. Second, by opening this competitors to everybody, we hope to foster novel options and make clear open challenges and alternatives.
The competitors might be hosted on Kaggle and run between mid-July 2023 and mid-September 2023. As a part of the competitors, in the present day we’re saying the provision of the beginning equipment. This beginning equipment supplies a basis for contributors to construct and check their unlearning fashions on a toy dataset.
The competitors considers a sensible state of affairs during which an age predictor has been educated on face photographs, and, after coaching, a sure subset of the coaching photographs should be forgotten to guard the privateness or rights of the people involved. For this, we are going to make accessible as a part of the beginning equipment a dataset of artificial faces (samples proven beneath) and we’ll additionally use a number of real-face datasets for analysis of submissions. The contributors are requested to submit code that takes as enter the educated predictor, the overlook and retain units, and outputs the weights of a predictor that has unlearned the designated overlook set. We are going to consider submissions based mostly on each the power of the forgetting algorithm and mannequin utility. We may also implement a tough cut-off that rejects unlearning algorithms that run slower than a fraction of the time it takes to retrain. A precious end result of this competitors might be to characterize the trade-offs of various unlearning algorithms.
 |
| Excerpt photographs from the Face Synthetics dataset along with age annotations. The competitors considers the state of affairs during which an age predictor has been educated on face photographs just like the above, and, after coaching, a sure subset of the coaching photographs should be forgotten. |
For evaluating forgetting, we are going to use instruments impressed by MIAs, reminiscent of LiRA. MIAs have been first developed within the privateness and safety literature and their objective is to deduce which examples have been a part of the coaching set. Intuitively, if unlearning is profitable, the unlearned mannequin comprises no traces of the forgotten examples, inflicting MIAs to fail: the attacker can be unable to deduce that the overlook set was, the truth is, a part of the unique coaching set. As well as, we may also use statistical assessments to quantify how totally different the distribution of unlearned fashions (produced by a selected submitted unlearning algorithm) is in comparison with the distribution of fashions retrained from scratch. For a great unlearning algorithm, these two might be indistinguishable.
Conclusion
Machine unlearning is a robust instrument that has the potential to deal with a number of open issues in machine studying. As analysis on this space continues, we hope to see new strategies which can be extra environment friendly, efficient, and accountable. We’re thrilled to have the chance through this competitors to spark curiosity on this discipline, and we’re trying ahead to sharing our insights and findings with the group.
Acknowledgements
The authors of this publish are actually a part of Google DeepMind. We’re scripting this weblog publish on behalf of the group group of the Unlearning Competitors: Eleni Triantafillou*, Fabian Pedregosa* (*equal contribution), Meghdad Kurmanji, Kairan Zhao, Gintare Karolina Dziugaite, Peter Triantafillou, Ioannis Mitliagkas, Vincent Dumoulin, Lisheng Solar Hosoya, Peter Kairouz, Julio C. S. Jacques Junior, Jun Wan, Sergio Escalera and Isabelle Guyon.
{kind=link}